시작하며
러스트 비동기 프로그래밍 세계에 오신 것을 환영합니다. 만약 러스트의 비동기 프로그래밍을 공부하신다면, 제대로 찾아오셨습니다. 웹서버나 데이터베이스, 또는 운영체제를 만든다면, 이 책이 하드웨어 성능의 대부분을 뽑아낼 수 있는 러스트 비동기 프로그래밍 방법를 알려드릴 것입니다.
이 책이 다루는 것들
이 책은 러스트에서 언어적으로 지원되는 비동기 기능과 라이브러리를 사용하기 위한 종합적이고 최신의 가이드를 초심자와 숙련자 모두에게 제공하고자 합니다.
-
이 책 초반에는 일반적인 비동기 프로그래밍과 러스트의 특별한 비동기 프로그래밍에 대해 소개합니다.
-
중반부에서는 비동기 코드를 작성할 때 사용되는 핵심 기능과 흐름제어 도구들에 대해 논의합니다. 그리고 라이브러리와 어플리케이션에 최고의 성능과 재사용성을 부여하기 위해 필요한 모범답안을 소개합니다.
-
종반부에서는 보다 넓은 비동기 생태계에 대해 설명하고, 보편적인 태스크들을 해결하는 방법에 대한 다양한 예제를 제공합니다.
자, 이제 흥미진진한 러스트의 비동기 프로그래밍 세계로 모험을 떠납시다!
역주 : 이 책은 미완성입니다.
원문과 이 번역본 모두 미완성입니다. 이 번역본을 읽다가 이해가 잘 되지 않으면, 원문을 참조하십시오. 원문을 읽어도 이해가 되지 않으면, 다른 비동기 학습자료를 추천합니다.
왜 비동기가 필요한가?
우리 모두는 러스트로 빠르고 안전한 소프트웨어를 작성할 수 있음을 잘 알고 있습니다. 그렇다면, 어떻게 해야 비동기 프로그래밍으로도 빠르고 안전한 소프트웨어를 만들 수 있을까요?
비동기 프로그래밍, 줄여서 비동기는 동시적 프로그래밍 모델 중 하나로서, 갈수록
많은 프로그래밍 언어가 지원하고 있습니다. 비동기는 async/await 문법을 통해,
평범한 동기 프로그래밍의 형태와 느낌을 비슷하게 가져가면서도, 적은 수의 운영체제
스레드 위에서 많은 수의 동시적 태스크를 실행할 수 있게 해줍니다.
비동기 vs 다른 동시성 모델
동시적 프로그래밍은 통상적인 절차적 프로그래밍보다 덜 성숙되었고, 덜 "표준화"되었습니다. 그 결과, 우리는 사용하는 언어가 어떤 동시적 프로그래밍 모델을 지원하는 지에 따라 동시성을 다르게 표현합니다.
가장 인기있는 동시성 모델에 대해 간단하게 알아보면서, 왜 비동기 프로그래밍이 좀더 폭넓은 동시적 프로그래밍 분야에 적합한지 이해해 봅시다.
- 운영체제 스레드는 프로그래밍 모델에 어떠한 변경도 필요하지 않아 동시성을 표현하기 매우 쉽습니다. 하지만, 스레드들을 동기화 하는 것이 어려울 수 있고, 성능 오버헤드가 큽니다. 스레드풀이 이러한 단점들을 완화해 줄 수 있지만, 대규모 입출력이 필요한 워크로드에 적용하기에는 역부족입니다.
- 이벤트-드리븐 프로그래밍은 콜백 과 연계하여 고성능을 낼 수 있지만, 종종 번잡한 "비선형" 흐름제어가 필요하게 됩니다. 보통 데이터 흐름과 에러 전파를 추적하기 어려워집니다.
- 코루틴은 스레드처럼 프로그래밍 모델을 변경할 필요가 없어 사용하기 쉽습니다. 또, 비동기처럼 많은 수의 태스크를 지원할 수도 있습니다. 하지만, 코루틴은 시스템 프로그래밍과 커스텀 런타임 구현에 필요한 저수준의 디테일을 추상화해 버립니다.
- 행위자 모델은 분산 시스템과 매우 흡사하게, 모든 동시적 연산을 행위자라는 기본 단위로 나누고, 행위자들이 실패가능한 메시지 전달체계를 통해 통신하게 합니다. 행위자 모델은 효율적으로 구현될 수 있지만, 흐름제어와 재시도 로직과 같은 해결되지 않은 많은 현실적인 문제들이 남아 있습니다.
요약하면, 비동기 프로그래밍은 스레드와 코루틴의 인간공학적 이득(역주: 편이성)을 제공하면서도, 러스트 같은 저수준 언어에 적합한 고성능의 구현을 가능하게 해줍니다.
러스트의 비동기 vs 다른 언어의 비동기
비록 비동기 프로그래밍이 많은 언어에서 지원된다고 하더라도, 몇몇 디테일들은 구현에 따라 다릅니다. Rust의 비동기 구현은 몇 가지 측면에서 다른 대다수의 언어들과 다릅니다.
- 러스트에서는 Future가 불활성(inert)이므로 오직 poll되었을 때에만 진행됩니다. future를 drop하면 더 이상 진행되지 않습니다.
- 러스트에서는 비동기가 제로 코스트이므로(런타임 오버헤드가 없으므로) 사용자가 실제 사용한 연산에 대해서만 비용을 지불하면 됩니다. 특히, 힙 할당과 동적 디스패치 없이도 비동기를 사용할 수 있으므로, 성능에 큰 이점이 됩니다.
- 러스트가 기본 제공하는 내장 런타임이 없고, 대신에 커뮤니티가 관리하는 크레잇을 통해 런타임이 제공됩니다.
- 러스트에서는 싱글과 멀티스레드 런타임 모두를 지원하며, 각각은 장단점이 있습니다.
러스트의 비동기 vs 스레드
러스트에서 비동기를 대체할 수 있는 첫번째는 선택지는 운영체제 스레드로,
std::thread를 이용해 직접적으로
사용하거나 또는 스레드풀을 이용하여 간접적으로도 사용할 수 있습니다. 스레드에서
비동기로 전환하거나 그 반대의 경우에도 보통 많은 양의 리팩토링이 필요합니다. 이
리팩토링 범위에는 구현과 (라이브러리를 만들고 있다면) 노출된 퍼블릭 인터페이스
둘 다 포함됩니다. 그렇기 때문에, 개발초기에 요구사항에 적합한 모델을 제대로
선정하여야 많은 개발 시간을 단축할 수 있습니다.
운영체제 스레드는 CPU와 메모리 오버헤드를 수반하기 때문에, 적은 수의 태스크에 적합합니다. 아이들 상태의 스레드도 시스템 자원을 소비하기 때문에 스레드 생성과 전환은 꽤 비쌉니다. 스레드풀 라이브러리는 이 비용들 중 일부만 줄여줄 뿐입니다. 하지만, 스레드를 이용하면 별다른 코드 변경없이 기존의 동기 코드를 재사용할 수 있으므로, 별도의 프로그래밍 모델이 필요 없습니다. 몇몇 운영체제에서는 스레드의 우선순위를 바꿀 수 있어서 장치 드라이버와 다른 지연시간에 민감한 어플리케이션을 만들 때 유용합니다.
비동기는 CPU와 메모리 오버헤드를 꽤 줄여주는 데, 특히, 서버와 데이터베이스 같은 대량의 입출력에 의존하는 태스크에서 효과가 큽니다. 나머지는 동일하며, 비동기 런타임은 태스크를 다룰 때 스레드보다 적은 비용을 사용하기 때문에, 운영체제 스레드보다 한 자릿수는 더 많은 태스크를 사용할 수 있습니다. 하지만, 비동기 러스트는 상태기계가 비동기 함수들로부터 생성되고, 실행파일마다 비동기 런타임이 포함되어야 하기 때문에, 바이너리 사이즈 증가를 초래합니다.
한 가지 더 말씀드리자면, 비동기 프로그래밍은 스레드보다 더 좋은 것이 아니라 다른 것입니다. 성능 측면에서 굳이 비동기가 필요하지 않다면, 보통 스레드가 보다 간단한 대안이 될 것입니다.
예제: 동시적 다운로드
이 예제의 목표는 두 개의 웹 페이지를 동시적으로 다운로드 하는 것입니다. 전형적인 스레드 어플리케이션이라면, 동시성을 위해 스레드를 생성하여야 합니다.
fn get_two_sites() {
// 태스크에 사용될 두 개의 스레드 생성
let thread_one = thread::spawn(|| download("https://www.foo.com"));
let thread_two = thread::spawn(|| download("https://www.bar.com"));
// 두 개의 스레드가 완료될 때까지 기다림
thread_one.join().expect("thread one panicked");
thread_two.join().expect("thread two panicked");
}
하지만, 웹 페이지를 다운로드는 작은 태스크이므로 스레드를 생성하는 것은 많은 낭비이고, 병목을 일으킬 수 있습니다. 비동기 러스트에서는, 이런 태스크들을 추가 스레드 없이 동시적으로 실행할 수 있습니다.
async fn get_two_sites_async() {
// 완성될때까지 실행된다면, 웹페이지를 비동기적으로 다운로드 할 두 개의 다른
// "future"를 만들기
let future_one = download_async("https://www.foo.com");
let future_two = download_async("https://www.bar.com");
// 두 개의 future를 완성될때까지 동시에 실행하기
join!(future_one, future_two);
}
여기서는, 추가적인 스레드를 생성하지 않았습니다. 게다가, 모든 함수 호출들이 정적으로 디스패치되었고, 힙 할당도 일어나지 않았습니다! 하지만, 처음 부분에서 코드를 비동기적으로 작성해야 했는데, 바로 이 책이 여러분에게 도움을 줄 부분입니다.
러스트의 커스텀 동시성 모델
마지막으로, 러스트는 스레드와 비동기 둘 중에 하나를 선택하도록 강요하지 않습니다. 한 어플리케이션에서 두 개의 모델 모두를 사용할 수 있으므로, 여러분이 스레드와 비동기에 복합적으로 의존할 때에 유용할 것입니다. 사실, 여러분은 (구현한 라이브러리만 있다면) 이벤트-드리븐 프로그래밍 같은 또 다른 동시성 모델도 사용할 수 있습니다.
비동기적 러스트 현황
비동기 러스트 중 일부는 동기적 러스트와 같은 수준의 안정성을 보장받고 있습니다. 나머지 부분들은 과도기에 있으며 향후 변경될 수 있습니다. 비동기 러스트에서는 아래와 같은 장단점들이 있습니다.
- 전형적인 동시적 워크로드에서 뛰어난 런타임 성능
- 수명이나 고정하기와 같은 러스트의 진보된 특징들과의 보다 빈번한 상호작용
- 동기와 비동기 코드에 사이에서, 그리고 서로 다른 비동기 런타임에 사이에서 발생하는 약간의 호환성 문제
- 비동기 런타임과 언어지원이 발전됨에 따라 발생하는 보다 높은 유지보수 부담
요약하면, 비동기 러스트는 사용하기 좀 어려워서 동기적 러스트보다 유지보수 부담이 큽니다만, 최상의 성능을 얻을 수 있습니다. 비동기 러스트의 모든 영역이 지속적으로 발전하고 있으므로, 문제점들은 시간이 갈 수록 완화될 것입니다.
언어 및 라이브러리 지원
비동기 프로그래밍은 러스트가 직접 지원하는 기능이지만, 대부분의 비동기 어플리케이션은 커뮤니티가 주도하는 크레잇들에 의존하고 있습니다. 마찬가지로, 여러분도 러스트 언어 기능과 라이브러리 지원을 복합적으로 사용해야 할 것입니다.
Future트레잇 같은 가장 기초적인 트레잇, 타입 그리고 함수는 표준 라이브러리에서 지원합니다.async/await문법은 러스트 컴파일러가 직접 지원합니다.- 수많은 유틸리티 타입, 매크로 그리고 함수들은
futures크레잇에서 지원합니다. 이것들은 모든 비동기 러스트 어플리케이션에서 사용가능합니다. - 비동기 코드, 입출력 그리고 작업 생성은 Tokio와 async-std 같은 "비동기 런타임"에서 제공됩니다. 대부분의 비동기 어플리케이션과 몇몇 비동기 크레잇은 특정 런타임에 의존합니다. 보다 자세한 내용은 "비동기 생태계" 장을 참조하세요.
여러분이 동기적 러스트에서 종종 사용했던 몇몇 러스트 기능들은 비동기 러스트에서는 아직 사용할 수 없습니다. 특히, 트레잇 안에서는 비동기 함수를 선언할 수 없습니다. 이같은 기능을 구현하려면 조금 번잡스러운 우회방법을 사용해야 합니다.
컴파일과 디버깅
비동기 러스트의 컴파일러와 런타임 에러들은 대부분 동기 러스트에서 작동했던 그것들과 같은 방식으로 작동합니다만, 주의할만한 차이점이 몇 개 있습니다.
컴파일 에러
비동기 러스트에서 컴파일 에러는 동기적 러스트의 높은 수준의 에러와 동일합니다만, 비동기 러스트가 수명이나 고정하기와 같은 좀더 복잡한 언어 기능을 사용하기 때문에, 이러한 에러가 좀더 빈번하게 나타날 것입니다.
런타임 에러
컴파일러는 비동기 함수를 맞닥트릴 때마다, 내부적으로 상태기계를 생성합니다. 비동기 러스트의 스택 추적들은 일반적으로 런타임의 함수호출 뿐만 아니라, 이런 상태기계의 세부사항을 포함합니다. 따라서, 스택 추적을 해석할 때도 동기적 러스트에서보다 고려할 것들이 더 있습니다.
새로운 실패 상황들
비동기 러스트에서는 몇가지 참신한 실패 상황들이 발생할 수 있습니다. 예를 들어,
블로킹 함수를 비동기 콘텍스트에서 호출하거나, Future 트레잇을 잘못 구현하는
경우들이 있습니다. 이같은 에러들은 컴파일러나 심지어 유닛 테스트에서도 발견되지
않을 수 있습니다. 이 책의 목표대로 여러분이 내부 컨셉과 구조를 완벽한
이해한다면, 이같은 문제들을 예방하는데 큰 도움이 될 것입니다.
호환성 검토
비동기와 동기적 코드를 항상 자유롭게 섞어 사용할 수 있는 것은 아닙니다. 예를 들어, 동기적 함수에서 비동기 함수를 직접 호출할 수는 없습니다. 동기, 비동기 코드는 서로 다른 디자인 패턴을 추구하는 경향이 있고, 따라서 다양한 환경을 지원하는 코드를 작성하기 어렵습니다.
심지어 비동기 코드끼리도 항상 자유롭게 섞어 사용할 수 있는 것은 아닙니다. 몇몇 크레잇은 특정한 비동기 런타임에 의존합니다, 보통 그런 경우, 특정한 비동기 런타임은 크레잇의 의존성 목록에 등재됩니다.
이러한 호환성 이슈들은 여러분의 선택지를 축소시키곤 합니다. 따라서 개발 초기에 어떤 비동기 런타임과 크레잇이 필요한지 충분히 고민하는 것이 좋습니다. 어떤 런타임에 정착하였다면, 호환성에 대하여 많은 고민을 할 필요가 없을 것입니다.
성능 특성
비동기 러스트의 성능은 여러분이 사용하는 비동기 런타임의 구현에 달려 있습니다. 비동기 러스트 어플리케이션에 사용되는 런타임들이 상대적으로 새로울지라도, 대부분의 실제 워크로드에서 매우 잘 작동합니다.
대부분의 비동기 생태계가 멀티 스레딩 런타임을 상정(想定)하였다고 말씀드렸습니다. 이 경우, 소위 저렴한 동기화라 불리는 싱글 스레딩 비동기 어플리케이션의 이론상 성능까지는 맛보기 힘들것입니다. 다른 간과된 용례는 장치 드라이버나 GUI 어플리케이션, 기타 등등에 중요한 지연시간에 민감한 태스크들 입니다. 이러한 태스크들은 적합한 스케쥴링을 위해 런타임에 의존하며, 운영체제 지원에 의존할 때도 있습니다. 향후 이러한 용례를 위한 라이브러리 지원의 향상을 기대하여도 좋을 것입니다.
async/.await 기초
async/.await는 동기적 코드처럼 생긴 비동기 함수들을 작성하는 데 쓰이는
러스트 내장 도구입니다. async는 코드 블록을 Future라는 트레잇을 구현하는
상태기계로 변환해줍니다. 동기적 메소드 안에서 블록하는 함수를 호출한다면 전체
스레드가 블록되지만, Future는 블록될 때 스레드를 놓아버리므로 다른
Future가 실행될 수 있습니다.
Cargo.toml 파일에 의존성을 추가해 봅시다.
[dependencies]
futures = "0.3"
비동기 함수를 만들기 위해, async fn 문법을 사용합니다.
#![allow(unused)] fn main() { async fn do_something() { /* ... */ } }
async fn이 반환하는 값은 한 개의 Future 객체입니다. 코드가 실제로 동작하게
하려면, executor로 Future 객체를 실행해야 합니다.
// `block_on`는 제공받은 future를 실행하여 완성될 때까지 현재의 스레드를 // 블록한다. 다른 종류의 executor는 여러 개의 future를 같은 스레드 안에서 // 스케줄링을 한다던가 하는 식으로 보다 복잡하게 동작한다. use futures::executor::block_on; async fn hello_world() { println!("hello, world!"); } fn main() { let future = hello_world(); // 아무것도 출력되지 않음 block_on(future); // `future` 가 실행되어 "hello, world!"가 출력됨 }
async fn 안에서 Future 트레잇을 구현한 다른 타입이 완성(예시: 다른 async fn의 출력 등)될 때까지 기다리려면 .await을 사용하면 됩니다. block on과
달리, .await는 현재의 스레드를 블록하지 않고, 대신에 해당 future가 완성될
때까지 비동기적으로 기다립니다. 이렇게 하면 해당 future가 현재 진행될 수 없는
상황에서도 다른 태스크들이 실행될 수 있습니다.
예를 들어, 세 개의 async fn(learn_song, sing_song 그리고 dance)이 있다고
칩시다.
async fn learn_song() -> Song { /* ... */ }
async fn sing_song(song: Song) { /* ... */ }
async fn dance() { /* ... */ }
노래를 배우고 부르며, 춤을 추기위한 방법 중에 하나는 각각을 수행할 때마다 블록하는 것입니다.
fn main() {
let song = block_on(learn_song());
block_on(sing_song(song));
block_on(dance());
}
그러나, 이 방법으로는 최선의 성능을 낼 수 없습니다. 오직 한 번에 한 가지만
한다구요! 우리가 노래를 부르기 전에 먼저 노래를 배워야 하는 것은 맞지만, 춤은
노래를 배우거나 부르면서도 출 수 있습니다. 이를 위해, 우리는 동시에 수행될 수
있는 두 개의 다른 async fn을 만들면 됩니다.
async fn learn_and_sing() {
// 노래를 부르기 전에 노래를 배울 때까지 기다림.
// 스레드를 블록하지 않기 위해 `block_on` 대신에 `.await`을 사용한다. 이렇게
// 하면, `춤`을 동시에 출 수 있다.
let song = learn_song().await;
sing_song(song).await;
}
async fn async_main() {
let f1 = learn_and_sing();
let f2 = dance();
// `join!`은 `.await`와 비슷하지만 여러 개의 future를 동시에 기다릴 수 있다.
// `learn_and_sing` future에서 일시적으로 블록되었더라도, `dance` future는
// 현재의 스레드를 가져올 것이다. `dance`가 블록되면, `learn_and_sing`은 다시
// 스레드를 가져올 수 있다. 둘 다 블록되면, `async_main`이 블록되고,
// executor에게 스레드를 양보할 것이다.
futures::join!(f1, f2);
}
fn main() {
block_on(async_main());
}
이 예제에서, 노래 배우기는 노래 부르기보다 먼저 동작해야 하지만, 노래 배우기와
부르기는 춤추기와 같은 시간에 동작할 수 있습니다. 만약 learn_and_sing안에서
learn_song().await말고, block_on(learn_song())을 사용했다면, 해당 스레드는
learn_song이 동작하는 동안에는 아무것도 할 수 없었을 것이고, 그렇다면 춤추기를
노래와 동시에 수행할 수 없었을 것입니다. 하지만 우리는 learn_song future를
.await함으로써, learn_song이 블록되었을지라도 다른 태스크들이 현재의
스래드에서 실행되게 할 수 있습니다. 이 방법으로, 여러 개의 future를 한 개의
스레드에서 동시에 실행하여 완성할 수 있습니다.
내부 구조: Future와 태스크 실행하기
이 장에서는, Future와 비동기 태스크들을 스케쥴링하는 세부적인 구조에 대해 다룰
것입니다. 만약 Future를 단순히 고수준에서 사용하는 방법에만 관심이 있고,
Future가 작동하는 세부 원리에 대해서는 관심이 없다면, async / await 장으로
건너뛰셔도 됩니다. 하지만, 이 장에서 다루는 여러 내용들은 async / await의
작동방식을 배우고, async / await 코드의 런타임과 성능요인을 이해하며,
새로운 비동기 primitives을 만드는 데 도움이 될 것입니다. 만약, 이 장을 건너뛰기로
하셨다면, 나중에라도 읽기 위해 북마크해놓으실 것을 추천합니다.
자, 이제 본격적으로 Future에 대해 알아봅시다.
Future 트레잇
Future 트레잇은 러스트 비동기 프로그래밍의 핵심입니다. Future는 비동기
연산으로서, 한 개의 값을 산출할 수 있습니다(그 값이 ()같은 빈
값일지라도요). 단순화된 버전의 future 트레잇은 다음과 같은 형태라고 할 수
있습니다.
#![allow(unused)] fn main() { trait SimpleFuture { type Output; fn poll(&mut self, wake: fn()) -> Poll<Self::Output>; } enum Poll<T> { Ready(T), Pending, } }
future는 poll 함수를 호출하면 진행됩니다. future가 완성될 때까지, poll
함수는 그때그때 가능한 만큼 future를 구동시킬 것입니다. 만약 future가
완성된다면, future는 Poll::Ready(result)를 반환합니다. future가 아직 완성될 수
없다면, future는 Poll::Pending을 반환하고, Future가 좀 더 진행될 준비가
되면 wake()함수가 호출되게 조치합니다. wake() 함수가 호출되면,
해당 Future를 구동(drive)하는 executor는 poll을 다시 호출하여 Future가 더
진행될 수 있게 합니다.
wake()가 없다면, executor는 어떤 future가 진행할 준비가 되었는지를 알 방법이
없어서, 아마 끊임없이 모든 future를 폴링(polling)해야만 할 것입니다. wake()
덕분에, executor는 어떤 future가 poll 될 수 있는지 정확히 알 수 있습니다.
예를 들어, 데이터를 제공할 준비가 됐는지 알 수 없는 소켓에서 데이터를 읽어야
하는 사례를 생각해봅시다. 만약 데이터가 있다면, 우리는 데이터를 읽어들여서
Poll::Ready(data)를 반환하면 됩니다. 하지만, 데이터가 준비되지 않았다면,
future는 블록될 것이고, 더 이상 진행할 수 없을 것입니다. 데이터가 준비되지
않았을 때에는, wake를 등록하여 나중에 소켓에 데이터가 준비되었을 때 wake가
호출될 수 있도록 합니다. 이렇게 등록하면 executor에게 우리의 future가 진행될
준비가 되었음을 알릴 수 있습니다. 간단한 SocketRead future는 다음과 같은
형태라고 할 수 있습니다.
pub struct SocketRead<'a> {
socket: &'a Socket,
}
impl SimpleFuture for SocketRead<'_> {
type Output = Vec<u8>;
fn poll(&mut self, wake: fn()) -> Poll<Self::Output> {
if self.socket.has_data_to_read() {
// 소켓에 데이터가 준비됨 -- 버퍼에 읽어 들이고 그 버퍼를 반환
Poll::Ready(self.socket.read_buf())
} else {
// 소켓에 아직 데이터가 준비되지 않음
//
// 데이터가 준비되면 `wake`가 호출될 수 있도록 조치함.
// 데이터가 준비되면, `wake`가 호출되고, 이 `Future`의 사용자는
// `poll`을 다시 호출하여 데이터를 읽을 수 있음을 알게 된다.
self.socket.set_readable_callback(wake);
Poll::Pending
}
}
}
여러 Future의 아래와 같은 구조는 여러 개의 비동기 연산들을 임시 할당 없이
한꺼번에 구성할 수 있게 해줍니다. 여러개의 future를 한 번에 실행하거나
연쇄실행하는 방식은 다음과 같이 할당 없는 상태기계로 구현될 수 있습니다.
/// 두 개의 다른 future를 실행하여 동시에 완성하는 SimpleFuture.
///
/// 각각의 future를 `poll`하는 호출이 교차로 이루어질 수 있어, 각 future가
/// 각자의 페이스대로 진행될 수 있게 해준다. 이를 통해 동시성을 얻을 수 있다.
pub struct Join<FutureA, FutureB> {
// 각 필드는 완성될 때까지 실행되어야 하는 future를 한 개씩 갖을 수 있다.
// 만약, future가 이미 완성되었다면, 그 필드는 `None`으로 설정된다.
// 이를 통해, future가 완성된 이후에 폴링하는 `Future` trait 규칙 위반을
// 예방할 수 있다.
a: Option<FutureA>,
b: Option<FutureB>,
}
impl<FutureA, FutureB> SimpleFuture for Join<FutureA, FutureB>
where
FutureA: SimpleFuture<Output = ()>,
FutureB: SimpleFuture<Output = ()>,
{
type Output = ();
fn poll(&mut self, wake: fn()) -> Poll<Self::Output> {
// future `a`를 완성하려고 시도함.
if let Some(a) = &mut self.a {
if let Poll::Ready(()) = a.poll(wake) {
self.a.take();
}
}
// future `b`를 완성하려고 시도함.
if let Some(b) = &mut self.b {
if let Poll::Ready(()) = b.poll(wake) {
self.b.take();
}
}
if self.a.is_none() && self.b.is_none() {
// 두 future 모두 완성되었음 -- 성공적으로 반환함
Poll::Ready(())
} else {
// 하나 또는 두 개의 future가 `Poll::Pending`을 반환하므로, 아직
// 해야 할 태스크가 남아 있다. future(들)은 진행이 가능할 때
// `wake()`를 호출할 것이다.
Poll::Pending
}
}
}
위 예제는 여러개의 future가 각각에 대한 할당 없이도 어떻게 동시에 실행 될 수 있는지 보여줍니다. 이는 보다 효율적인 비동기 프로그램입니다. 마찬가지로, 순서가 있는 여러개의 future는 아래와 같이 한 개 한 개 씩 실행될 수 있습니다.
/// 두 개의 future가 완성될 때까지 순차적으로 실행하는 SimpleFuture
//
// 주의: 이 간단한 예제의 취지에 맞도록, `AndThenFut`은 첫 번째와 두 번째
// future 둘 다 생성시에 활성화되었다고 가정한다. 진짜 `AndThen` 조합자는
// `get_breakfast.and_then(|food| eat(food))`처럼 첫 번째 future의
// 결과에 따라 두 번째 future를 만들 수 있다.
pub struct AndThenFut<FutureA, FutureB> {
first: Option<FutureA>,
second: FutureB,
}
impl<FutureA, FutureB> SimpleFuture for AndThenFut<FutureA, FutureB>
where
FutureA: SimpleFuture<Output = ()>,
FutureB: SimpleFuture<Output = ()>,
{
type Output = ();
fn poll(&mut self, wake: fn()) -> Poll<Self::Output> {
if let Some(first) = &mut self.first {
match first.poll(wake) {
// 첫 번째 future가 완성되었다 -- 첫 번째를 제거하고 두 번째
// future를 시작한다!
Poll::Ready(()) => self.first.take(),
// 첫 번째 future도 완성되지 못했다.
Poll::Pending => return Poll::Pending,
};
}
// 이제 첫 번재 future가 완성되었으니, 두 번째 future를 완성하려고
// 시도한다.
self.second.poll(wake)
}
}
위의 예제들은 Future 트레잇이 여러개의 할당된 객체나 반복중첩된(deeply nested)
콜백 없이 비동기 흐름 제어를 구현하는 방법을 보여줍니다. 기본적인 흐름제어에
대한 설명은 이쯤에서 마치고, 진짜 Future 트레잇은 실제로 어떻게 생겼고, 무엇이 다른지
살펴봅시다.
trait Future {
type Output;
fn poll(
// `&mut self`에서 `Pin<&mut Self>`로 변화되었음:
self: Pin<&mut Self>,
// `wake: fn()`에서 `cx: &mut Context<'_>`로 변화되었음:
cx: &mut Context<'_>,
) -> Poll<Self::Output>;
}
여러분이 확인하게 된 첫 번째 변화는 self 타입이 더 이상 &mut Self가 아니고,
Pin<&mut Self>로 바뀌었다는 점입니다. 다른 장에서 고정하기에
대해 더 다루겠지만, 지금은 이동불가한 future를 만들 수 있게 해준다는 점만 알아
두십시오. 이동불가한 객체는 struct MyFut { a: i32, ptr_to_a: *const i32 } 처럼
필드에 포인터를 저장할 수 있습니다. 고정하기는 async와 await를 활성화하기
위해 필요합니다.
두 번째로, wake: fn()은 &mut Context<'_>으로 바뀌었습니다.
SimpleFuture에서는 future executor에게 진행할 준비가 된 것으로 보이는 future가
poll되어야 한다고 알려주기 위해 함수포인터(fn())에 대한 호출을
사용하였습니다. 하지만, fn()은 단지 함수포인터일 뿐, 어떤 Future가
wake를 호출했는지에 대한 정보를 저장할 수 없습니다.
현실적인 시나리오에서, 웹 서버 같은 복잡한 어플리케이션에는 수 천개의 커넥션이
있을 것이고, 각 연결에 대한 wakeup은 모두 개별적으로 관리되어야 할 것입니다.
Waker 타입의 값에 대한 접근을 제공하는 Context 타입을 이용하여 이를 해결하는
데, 이 Context로 특정한 태스크를 깨울 수 있습니다.
Waker로 태스크 깨우기
future들이 첫 번째 poll에서는 완성되지 못하는 것이 일반적입니다. 완성되지
못했을 경우, 더 진행이 가능할 준비가 되면 future가 poll될 수 있게 확실히
조치해둘 필요가 있습니다. Waker 타입으로 이 조치를 취할 수 있습니다.
future가 poll될 때마다 한 "태스크"의 일부분으로서 poll됩니다. 태스크란 한 executor에게 제공된 최상위 future들입니다.
Waker는 wake() 메소드를 제공하는데, 이 메소드는 연관된 태스크가 깨워져야
한다고 executor에게 알리는데 사용됩니다. wake()가 호출되었을 때, executor는
Waker와 연관된 태스크가 진행될 준비가 되었으며, 태스크의 future가 다시
poll되어야 한다는 것을 알게 됩니다.
Waker는 clone()도 구현하기 때문에, 필요한 곳에 복사되고 저장될 수 있습니다.
Waker를 사용하여 간단한 타이머를 구현해 봅시다.
응용: 타이머 만들기
이 예제의 목적에 따라, 우리는 타이머가 만들어졌을 때 그냥 새 스레드를 하나 생성할 것이고, 필요한 만큼 sleep할 것입니다. 그리고 time window가 지나면, 타이머 future에 시그널을 보낼 것입니다.
먼저, cargo new --lib timer_future를 실행하여 새 프로젝트를 만들고, imports를
추가합시다. 그리고 src/lib.rs파일에 코딩하면서 시작합니다.
#![allow(unused)] fn main() { use std::{ future::Future, pin::Pin, sync::{Arc, Mutex}, task::{Context, Poll, Waker}, thread, time::Duration, }; }
먼저 future 타입 자체를 정의합시다. 우리의 future에게는 타이머가 경과되었는지,
그래서 future가 완성되어야 하는지 여부를 스레드와 통신할 방법이 필요합니다.
그래서 공유된 Arc<Mutex<..>> 값을 사용해서 스레드와 future 사이에 통신할
것입니다.
pub struct TimerFuture {
shared_state: Arc<Mutex<SharedState>>,
}
/// future와 대기중인 스레드 사이에 공유되어 상태를 나타내는 구조체
struct SharedState {
/// 타이머가 경과되었는 지 여부
completed: bool,
/// `TimerFuture`가 실행될 태스크 용 waker.
/// 스레드는 `completed = true`라고 설정한 후에 `TimerFuture`의 태스크에게
/// "일어나서, `completed = true`인지 확인하고, 진행하라"고 전하는 데 이
/// waker를 사용할 수 있다.
waker: Option<Waker>,
}
자, 진짜로 Future 구현을 작성해 봅시다.
impl Future for TimerFuture {
type Output = ();
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
// 타이머가 이미 완성되었는지 알기 위해 공유된 상태를 확인.
let mut shared_state = self.shared_state.lock().unwrap();
if shared_state.completed {
Poll::Ready(())
} else {
// waker를 설정해서 타이머가 완성되었을 때 스레드가 현재의 태스크를
// 깨울 수 있게 한다. 이렇게 함으로써 future는 다시 poll 될 수 있으며,
// 또, `completed = true`가 맞는지 확인 할 수 있다.
//
// "waker를 매번 반복적으로 클론하지 않고 한 번만 해도 되지
// 않을까" 생각할 수도 있다. 하지만, `TimerFuture`는 executor의 여러
// 태스크로 이동할 수 있기 때문에, 클론을 한 번만 하면 잘못된
// 태스크를 가리키는 정체된 waker가 만들어져 `TimerFuture`가 제대로
// 못 깨워질 것이다.
//
// 주의: `Waker::will_wake` 함수를 이용하여 `TimerFuture`가
// 제대로 못 깨워지는 문제를 체크할 수 있으나, 예제를 간단하게
// 하기 위해 생략하였다.
shared_state.waker = Some(cx.waker().clone());
Poll::Pending
}
}
}
꽤 간단하죠? 스레드가 shared_state.completed = true로 설정하였다면 future가
완성된 것입니다. 아니라면, 우리는 스레드가 태스크를 다시 깨울 수 있도록,
Waker를 현재의 태스크용으로 클론하여 shared_state.waker에 전달합니다.
중요한 점은, future가 poll될 때마다 Waker를 갱신해야 한다는 점입니다.
왜냐하면, 그 future가 다른 Waker와 함께 다른 태스크로 이동했을 수 있기
때문입니다.(TODO: 의역필요) 이런 상황은 future가 poll되고 나서 태스크 사이에서
여기저기 전달될 때 발생합니다.
마지막으로, 실제로 타이머를 만들고 스레드를 시작할 API가 필요합니다.
impl TimerFuture {
/// 주어진 시간이 경과하면 완성되는 새로운 `TimerFuture`를 만든다.
pub fn new(duration: Duration) -> Self {
let shared_state = Arc::new(Mutex::new(SharedState {
completed: false,
waker: None,
}));
// 새로운 스레드 생성
let thread_shared_state = shared_state.clone();
thread::spawn(move || {
thread::sleep(duration);
let mut shared_state = thread_shared_state.lock().unwrap();
// 타이머가 완성되어서 future가 poll된 마지막 태스크를 (존재한다면)
// 깨우는 시그널
shared_state.completed = true;
if let Some(waker) = shared_state.waker.take() {
waker.wake()
}
});
TimerFuture { shared_state }
}
}
짠! 이게 간단한 타이머 future를 만드는데 필요한 전부입니다. 이제 future가 실행될 executor만 있으면 되는데요...
응용: executor 구현하기
러스트 Future는 지연계산됩니다. 완성시키기 위해 실제로 구동하기 전까지
future는 아무것도 하지 않을 것입니다. future를 완성까지 구동하는 한 가지 방법은
async 함수 안에서 future를 .await하는 것입니다. 다만, 그렇게 하면 문제가
하나 생깁니다: 누가 최상위 async 함수로부터 반환된 future를 실행할 것인가라는
문제입니다. 그리고 그 해답은 Future executor입니다.
Future executor는 최상위 Future의 집합을 받아 Future가 진행할 수 있을
때마다 poll을 호출해서 완성될 때까지 실행합니다. 일반적으로, executor는
시작하면서 future를 한 번 poll합니다. Future가 wake()를 호출하여 진행할
준비가 되었음을 알릴 때, future는 큐 뒤에 넣어지고, poll이 다시 호출됩니다.
이는 Future가 완성될 때까지 반복됩니다.
이 장에서 우리는 수많은 최상위 future를 완성될 때까지 동시에 실행할 수 있는 간단한 executor를 만들 것입니다.
이 예제에서는 Waker를 쉽게 만들 수 있게 도와주는 ArcWake 트레잇 때문에
futures 크레잇이 필요합니다. Cargo.toml을 수정하여 새 의존성을 추가하세요.
[package]
name = "timer_future"
version = "0.1.0"
authors = ["XYZ Author"]
edition = "2018"
[dependencies]
futures = "0.3"
다음은, src/main.rs의 맨 위에 아래와 같이 import합니다.
use {
futures::{
future::{BoxFuture, FutureExt},
task::{waker_ref, ArcWake},
},
std::{
future::Future,
sync::mpsc::{sync_channel, Receiver, SyncSender},
sync::{Arc, Mutex},
task::Context,
time::Duration,
},
// 이전 장에서 작성한 타이머
timer_future::TimerFuture,
};
실행할 태스크를 채널을 통해 보내면 우리의 executor가 작동할 겁니다. executor는 채널에서 이벤트를 당겨와서 실행합니다. 만약, 어떤 태스크가 조금 더 일 할 준비가 됐다면(즉, 깨워진다면), 그 태스크는 자기가 다시 poll될 수 있게 채널에 자기 스스로를 넣습니다.
이러한 설계 덕분에, executor는 그저 태스크 채널의 수신 단말만 있으면 됩니다. 유저에게는 송신 단말이 주어지므로, 새로은 future를 만들 수 있습니다. 태스크라는 것은 결국 스스로를 다시 스케쥴링할 수 있는 future일 뿐입니다. 따라서, 우리는 태스크들을 송신자(sender)와 짝지운 future의 형태로 저장할 것입니다. 송신자는 태스크가 자기자신을 큐에 넣는데 사용됩니다.
/// 채널에서 태스크를 받아서 실행하는 태스크 executor
struct Executor {
ready_queue: Receiver<Arc<Task>>,
}
/// 새 future를 태스크 채널에 생성해 넣는 `Spawner`
#[derive(Clone)]
struct Spawner {
task_sender: SyncSender<Arc<Task>>,
}
/// `Executor`에게 poll될 수 있게 스스로를 재스케줄링하는 future
struct Task {
/// 완성되기 위해서 큐에 넣어져야 하는, 진행중인 future
///
/// 정확히 하자면, `Mutex`가 꼭 필요한 것은 아니다. 우리는 한 시점에
/// (future들을 실행하는) 오직 하나의 스레드만 가지고 있기 때문이다. 하지만,
/// 러스트는 우리의 `future`가 한 개의 스레드 안에서만 변경된다는 사실을 알
/// 수 없기 때문에, 우리는 스레드 안전성을 위해 `Mutex`를 사용해야만 한다.
/// 현업에서는 `Mutex` 대신 `UnsafeCell`을 사용할 수도 있다.
future: Mutex<Option<BoxFuture<'static, ()>>>,
/// 태스크가 자기자신을 태스크 큐의 마지막에 넣는데 사용되는 핸들
task_sender: SyncSender<Arc<Task>>,
}
fn new_executor_and_spawner() -> (Executor, Spawner) {
// 채널(큐)이 일시점에 가질 수 있는 태스크의 최대 갯수.
// 그냥 `sync_channel`을 만드는데 필요한 것이고, 실제 executor에 적용될 일은
// 없을 것이다.
const MAX_QUEUED_TASKS: usize = 10_000;
let (task_sender, ready_queue) = sync_channel(MAX_QUEUED_TASKS);
(Executor { ready_queue }, Spawner { task_sender })
}
새 future를 만들기 쉽게 메소드 한 개를 더 spawner에 추가합시다. 이 메소드는
future 타입을 받아서, box로 감싸고, 새 Arc<Task>로 만들 것입니다.
새로 만든 Arch<Task>는 excutor에게 enqueue될 것입니다.
impl Spawner {
fn spawn(&self, future: impl Future<Output = ()> + 'static + Send) {
let future = future.boxed();
let task = Arc::new(Task {
future: Mutex::new(Some(future)),
task_sender: self.task_sender.clone(),
});
self.task_sender.send(task).expect("큐에 태스크가 너무 많습니다.");
}
}
future를 poll하기 위해서는, Waker를 생성해야 합니다. 태스크 깨우기 section에서
설명했듯이, Waker는 wake가 호출되면 태스크가 다시 poll될 수 있도록
스케쥴링합니다. Waker들은 executor에게 정확히 어떤 태스크가 준비되었는지
알려주기 때문에, executor는 진행할 준비가 된 future들만 poll한다는 점을
기억하십시오. 새로운 Waker를 만드는 가장 쉬운 방법은 ArcWake 트레잇을
구현하고, waker_ref나 .into_waker() 함수를 이용하여 Arc<impl ArcWake>를
Waker로 변경하는 것입니다. 우리의 태스크를 위한 ArcWake를 구현하여 Waker로
변경하고 깨워봅시다.
impl ArcWake for Task {
fn wake_by_ref(arc_self: &Arc<Self>) {
// `wake`를 이 태스크를 다시 태스크 채널에 보내는 방식으로 구현한다. 그래서
// executor가 이 태스크를 다시 poll할 것이다.
let cloned = arc_self.clone();
arc_self
.task_sender
.send(cloned)
.expect("큐에 태스크가 너무 많습니다.");
}
}
Arc<Task>로부터 만들어진 Waker의 wake()를 호출하면 Arc의 복사본이 태스크
채널로 송신될 것이다. 그러면 우리의 executor는 그 태스크를 집어 poll해야 한다.
구현해 봅시다.
impl Executor {
fn run(&self) {
while let Ok(task) = self.ready_queue.recv() {
// future를 취하고 나서, 아직 future가 완성되지 않았으면(아직 Some이면),
// future를 완성하기 위해 poll한다.
let mut future_slot = task.future.lock().unwrap();
if let Some(mut future) = future_slot.take() {
// task 자기자신으로부터 `LocalWaker`를 생성한다.
let waker = waker_ref(&task);
let context = &mut Context::from_waker(&*waker);
// `BoxFuture<T>`는 `Pin<Box<dyn Future<Output = T> + Send +
// 'static>>`의 type alias이다.
// `Pin::as_mut` 메소드를 호출하여 `BoxFuture<T>`로부터
// `Pin<&mut dyn Future + Send + 'static>`을 얻을 수 있다.
if future.as_mut().poll(context).is_pending() {
// future의 처리가 끝나지 않았으므로, 그것의 task에 도로
// 넣어서 미래에 다시 실행될 수 있게 한다.
*future_slot = Some(future);
}
}
}
}
}
축하합니다! future executor를 완성하였습니다. 여러분이 만든 executor를
asycn/.await 코드나 우리가 아까 만든 TimeFuture같은 커스텀 future를
실행하는데도 사용할 수 있습니다.
fn main() {
let (executor, spawner) = new_executor_and_spawner();
// 타이머 전후로 문자열을 출력할 태스크를 생성한다.
spawner.spawn(async {
println!("howdy!");
// 우리의 타이머 future가 2초 후에 완성될 때까지 기다린다.
TimerFuture::new(Duration::new(2, 0)).await;
println!("done!");
});
// 여러분의 executor가 spawner가 끝났음을 확인하고 더 이상 실행할 task를
// 받지 않도록 spawner를 drop한다.
drop(spawner);
// excutor를 task 큐가 빌 때까지 실행한다. "howdy!" 출력, 일시중지,
// "done!"출력 순으로 동작할 것이다.
executor.run();
}
Executor와 시스템 입출력
우리는 이전 Future 트레잇 장에서 소켓을 비동기적으로 읽는 아래의 future
예제에 대해 살펴보았습니다..
pub struct SocketRead<'a> {
socket: &'a Socket,
}
impl SimpleFuture for SocketRead<'_> {
type Output = Vec<u8>;
fn poll(&mut self, wake: fn()) -> Poll<Self::Output> {
if self.socket.has_data_to_read() {
// 소켓에 데이터가 준비됨 -- 버퍼에 읽어 들이고 그 버퍼를 반환
Poll::Ready(self.socket.read_buf())
} else {
// 소켓에 아직 데이터가 준비되지 않음
//
// 데이터가 준비되면 `wake`가 호출될 수 있도록 조치함.
// 데이터가 준비되면, `wake`가 호출되고, 이 `Future`의 사용자는
// `poll`을 다시 호출하여 데이터를 읽을 수 있음을 알게 된다.
self.socket.set_readable_callback(wake);
Poll::Pending
}
}
}
이 future는 소켓에 준비된 데이터를 읽어들이지만, 준비된 데이터가 없다면
executor에게 "소켓에 데이터가 준비되면 future의 태스크를 다시 깨워주세요"라고
요청하면서 콘텍스트를 양보할 것입니다. 하지만, 이 예제에서는 Socket 타입이
어떻게 구현되는지 확실하지 않고, 특별히 set_readable_callback 함수가
작동하는지가 분명하지 않습니다. 어떻게 하면 소켓에 데이터가 준비되었을 때,
wake()가 호출될 수 있게 할까요? 끊임없이 socket이 준비되었는지 확인하여
맞으면 wake()를 호출하는 스레드를 하나 만드는 것도 선택지가 될 것입니다.
그러나 이 방법은 블록된 입출력 future 각각마다 별개의 스레드가 필요하기 때문에
매우 비효율적이어서 우리의 비동기 코드의 효율을 크게 저하시킬 것입니다.
사실 이 문제는 입출력과 연계된 시스템 블로킹 기본기능과 통합으로 해결합니다.
예를 들면 리눅스의 epoll, FreeBSD와 Mac OS의 kqueue, 윈도우즈의 IOCP,
퓨시아의 port같은 것들이 있습니다(그리고 이것들 모두는 크로스 플랫폼 려스트
크레잇인 mio를 이용하여 사용할 수 있습니다). 이러한 기본기능들은 모두 한
스레드가 여러개의 비동기 입출력 이벤트에 따라 블록하였다가 이벤트가 완성되면
반환할 수 있는 기능을 제공합니다. 이러한 API들은 실제로 보통 아래와 같은
형태입니다.
struct IoBlocker {
/* ... */
}
struct Event {
// 생성되어 전파되는 이벤트를 고유하게 식별하는 ID_
id: usize,
// 기다리고 있거나, 발생된 시그널 집합
signals: Signals,
}
impl IoBlocker {
/// 발생하면 블록할 비동기 입출력 이벤트의 새로운 컬렉션을 만든다.
fn new() -> Self { /* ... */ }
/// 특정 입출력 이벤트에 interest를 표시한다.
fn add_io_event_interest(
&self,
/// 이벤트가 발생할 오브젝트
io_object: &IoObject,
/// 이벤트가 발동되어야 하는 `io_object`에 발생할 시그널들의 집합으로,
/// 이 interest로부터 비롯된 이벤트에 부여될 ID와 짝지워진다.
event: Event,
) { /* ... */ }
/// 이벤트 중에 하나가 발생할 때까지 블록한다.
fn block(&self) -> Event { /* ... */ }
}
let mut io_blocker = IoBlocker::new();
io_blocker.add_io_event_interest(
&socket_1,
Event { id: 1, signals: READABLE },
);
io_blocker.add_io_event_interest(
&socket_2,
Event { id: 2, signals: READABLE | WRITABLE },
);
let event = io_blocker.block();
// 소켓에 데이터가 준비되면 "Socket 1 is now READABLE" 같은 걸 출력한다.
println!("Socket {:?} is now {:?}", event.id, event.signals);
future의 executor들은 아래의 기본기능들을 비동기 입출력 객체를 제공하기 위해
사용할 수 있습니다. 예를 들어, 소켓은 특별한 입출력 이벤트가 발생하였을 때, 콜백이
실행되도록 설정할 수 있습니다. 위의 SocketRead 예제의 경우에
Socket::set_readable_callback 함수는 아래와 같은 의사코드와 비슷한 형태일
것입니다.
impl Socket {
fn set_readable_callback(&self, waker: Waker) {
// `local_executor`는 로컬 executor에 대한 레퍼런스이다.
// `local_executor`는 소켓 생성시에 제공될 수도 있었겠지만, 실제로는
// 편의상 많은 executor 구현에서 스레드의 로컬 스토리지에
// 두고 사용한다.
let local_executor = self.local_executor;
// 이 입출력 객체의 고유 ID
let id = self.id;
// executor의 맵에 로컬 waker를 저장하여 입출력 이벤트가
// 도착하면 로컬 wake가 호출될 수 있다.
local_executor.event_map.insert(id, waker);
local_executor.add_io_event_interest(
&self.socket_file_descriptor,
Event { id, signals: READABLE },
);
}
}
이로써 우리는 어떤 입출력 이벤트라도 받아서 딱맞는 Waker에게 보내줄 수 있는
executor 스레드를 만들었습니다. 그리고 Waker는 이벤트에 대응하는 태스크를 깨울
것입니다. 또, executor는 입출력 이벤트를 더 확인하기 전에 보다 많은 태스크들을
완성될까지 구동할 수 있을 것입니다(그리고 사이클은 반복됩니다...).
async/.await
첫 장에서 우리는 async/.await을 짧게 다뤘습니다. 이제 async 코드가
어떻게 동작하고, 어떻게 전형적인 러스트 프로그램과 다른지 더 자세히 들여다봅시다.
async/.await는 현재 실행중인 스레드를 블로킹하지 않고 제어권을 놓아줄 수
있게 만들어주는 특별한 러스트 문법입니다. 이를 통해 어떤 명령이 완성될 때까지
기다리면서(역주 : 예를 들어, 소켓에 데이터가 들어오기를 기다린다던가) 다른
코드들이 실행될 수 있습니다.
async를 다루는 주 방법에는 두 가지, async fn과 async 블록이 있습니다. 각각
Future 트레잇을 구현한 값을 반환합니다.
// `foo()`는 `Future<Output = u8>`을 구현한 타입을 반환합니다.
// `foo().await`의 결과는 `u8` 타입의 값입니다.
async fn foo() -> u8 { 5 }
fn bar() -> impl Future<Output = u8> {
// 이 `async` 블록은`Future<Output = u8>`을 구현한
// 타입을 반환합니다.
async {
let x: u8 = foo().await;
x + 5
}
}
첫 장에서 봤듯이, async 안쪽과 그 밖의 future 구현체는 게으릅니다. 즉 실행될
때까지 아무 일도 안 합니다. Future를 실행하는 통상적인 방법은 Future에
.await를 사용하는 것입니다. Future가 .await되면, 그 Future가 완료될
때까지 실행하려고 할 것입니다. 하지만, Future가 실행 도중에 블록되면 현재
스레드의 제어를 놓아줍니다. 그리고 Future가 더 진행이 될 수 있는 상황이
돌아오면, Future는 실행자에게 선택돼 실행을 재개할 것이고, 따라서 .await이
완료될 수도 있을 것입니다.(역주 : 물론 Future가 다시 블록될 수도 있다)
async한 수명
참조나 기타 'static하지 않은 인자를 취하는 async fn은 다른 전형적인 함수들과
달리 인자의 수명에 묶인(bound) Future를 반환합니다.
// 이 함수는
async fn foo(x: &u8) -> u8 { *x }
// 이 함수와 같습니다.
fn foo_expanded<'a>(x: &'a u8) -> impl Future<Output = u8> + 'a {
async move { *x }
}
즉, async fn에서 반환된 future는 자신이 받은 'static이 아닌 인자가 유효한
상태에서만(역주 : 즉, 참조의 수명 범위내에서만) .await되어야 합니다. 보통
foo(&x).await와 같이 함수를 호출하고 바로 future를 .await할 때는 문제가
없습니다. 허나 future를 또다른 작업이나 스레드로 저장하거나 보내면 문제가 생길
수 있습니다.
참조를 인자로 가진 async fn을 'static한 future로 바꾸는 유용한 방법은 바로
async fn의 호출과 인자를 하나의 async 블록 안에 두는 것입니다.
fn bad() -> impl Future<Output = u8> {
let x = 5;
borrow_x(&x) // ERROR: `x`의 수명이 충분하지 않습니다.
}
fn good() -> impl Future<Output = u8> {
async {
let x = 5;
borrow_x(&x).await
}
}
인자를 async 블록 안으로 옮기면, 그 인자의 수명을 늘리기 때문에 good을
호출하여 반환되는 Future의 수명과 일치시킬 수 있습니다.
async move
async 블록과 클로저는 보통 클로저처럼 move 키워드를 허용합니다. async move
블록은 자신이 참조하는 변수의 소유권을 획득하면서, 그 변수를 원래의 스코프
바깥에서도 유효하게 만들 것이지만, 다른 코드는 그 변수를 사용할 수 없게 됩니다.
/// `async` 블록:
///
/// 서로 다른 여러 개의 `async` 블록들은, 어떤 지역 변수의 스코프 안에서
/// 실행되는 한, 그 지역 변수에 함께 접근할 수 있습니다.
async fn blocks() {
let my_string = "foo".to_string();
let future_one = async {
// ...
println!("{my_string}");
};
let future_two = async {
// ...
println!("{my_string}");
};
// 두 future를 완전히 실행해 "foo"를 두 번 출력합니다:
let ((), ()) = futures::join!(future_one, future_two);
}
/// `async move` 블록:
///
/// 오직 한 개의 `async move` 블록만 (역주: 그 `async move` 블록이) 캡쳐한
/// 변수에 접근할 수 있습니다. 왜냐하면, 캡쳐된 변수는 `async move` 블록이
/// 생성한 `Future`의 안으로 이동하기 때문입니다.
///
/// 반면에, 이렇게 함으로써 `Future`가 그 변수의 원래 스코프 밖에서도 실행될 수
/// 있게 됩니다.
fn move_block() -> impl Future<Output = ()> {
let my_string = "foo".to_string();
async move {
// ...
println!("{my_string}");
}
}
멀티스레드 실행자 상에서 .await하기
멀티스레드 용 Future 실행자를 사용하면, 모든 .await은 종종 새로운 스레드에서
Future를 실행시킬 수도 있습니다. 따라서 Future가 스레드를 갈아타는 상황이
생길 것이고, 당연히 async 블록 안쪽에서 쓰인 모든 변수도 반드시 스레드를
갈아탈 수 있어야 합니다.
그 말인 즉슨 Sync 트레잇을 구현하지 않는 타입에 대한 참조를 포함, Send
트레잇을 구현하지 않는 Rc, &RefCell 등 어떠한 타입도 안전하게 사용할 수
없다는 뜻입니다.
(주의: 이러한 타입들이 .await을 호출하는 스코프 안에 존재하지 않는다면,
사용할 수 있긴 있습니다.)
비슷하게, future를 고려하지 않고 만들어진 전통적인 락(lock)을 .await을 사이에
두고 사용하는 것은 좋지 않습니다. 왜냐하면 스레드풀을 잠궈버릴 수도 있기
때문입니다. 예를 들어, 한 태스크가 락 하나를 가져온 상태에서 .await하고
실행자에게 (역주: 현재 실행중인 스레드를) 내어준 경우, 다른 태스크가 다시 그
락을 가지려고 하면 데드락이 발생합니다. 이런 상황을 방지하기 위해, 이런 문제를
방지하기 위해 std::sync말고 futures::lock에 있는 Mutex를 사용하시기
바랍니다.
고정하기(Pinning)
future를 poll하기 위해서는, future가 Pin<T>라는 특별한 타입으로 고정되어
있어야 합니다. 이전 "Future와 태스크 실행하기" 장의 Future 트레잇을
읽었다면, Future::poll 메소드의 정의에서 self Pin<&mut Self>에 쓰였던
Pin을 보았을 것입니다. 그렇다면 Pin은 무슨 의미이고, 왜 필요할까요?
왜 고정해야 하나요
Pin은 Unpin 마커와 쌍으로 작동합니다. 고정하기는 !Unpin을 구현하는 객체가
절대 움직이지 않음을 보장하여 줍니다. 이게 왜 필요한지 이해하려면, async /
.await가 작동하는 방식을 떠올려 보세요. 아래 코드를 살펴봅시다.
let fut_one = /* ... */;
let fut_two = /* ... */;
async move {
fut_one.await;
fut_two.await;
}
보이지는 않지만, 위 코드는 Future를 구현하는 익명 타입을 만들어, 아래와 같은
poll 메소드를 제공합니다.
// 위 `async { ... }` 블록이 생성한 `Future` 타입
struct AsyncFuture {
fut_one: FutOne,
fut_two: FutTwo,
state: State,
}
// 위 `async`블록이 될 수 있는 상태의 종류
enum State {
AwaitingFutOne,
AwaitingFutTwo,
Done,
}
impl Future for AsyncFuture {
type Output = ();
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> {
loop {
match self.state {
State::AwaitingFutOne => match self.fut_one.poll(..) {
Poll::Ready(()) => self.state = State::AwaitingFutTwo,
Poll::Pending => return Poll::Pending,
}
State::AwaitingFutTwo => match self.fut_two.poll(..) {
Poll::Ready(()) => self.state = State::Done,
Poll::Pending => return Poll::Pending,
}
State::Done => return Poll::Ready(()),
}
}
}
}
poll이 처음 호출되면 poll은 fut_one을 poll할 것입니다. 만약 fut_one이
완성될 수 없다면, AsyncFuture::poll은 Poll::Pending을 반환할 것입니다.
다시 future의 poll을 호출하면 이전 future가 중단된 지점부터 다시 시작할 것입니다.
이 과정은 future가 성공적으로 완성될 때까지 반복될 것입니다.
하지만, async 블록이 참조를 사용한다면 어떻게 될까요?
예를 들어:
async {
let mut x = [0; 128];
let read_into_buf_fut = read_into_buf(&mut x);
read_into_buf_fut.await;
println!("{:?}", x);
}
위 코드는 어떤 구조체로 변환될까요?
struct ReadIntoBuf<'a> {
buf: &'a mut [u8], // 아래 `x`를 가리킴
}
struct AsyncFuture {
x: [u8; 128],
read_into_buf_fut: ReadIntoBuf<'what_lifetime?>,
}
여기 ReadIntoBuf future는 우리 구조체의 다른 필드인 x를 가리키는 참조를
가지고 있습니다. 따라서, AsyncFuture가 옮겨진다면, x의 위치도 같이 움직이면서
read_into_buf_fut.buf에 저장된 포인터도 무효화 될 것입니다.
future를 특정된 메모리 위치에 고정함으로서 이 문제를 방지하고, async 블록 안에
있는 값에 대한 참조를 안전하게 만들 수 있습니다.
고정하기에 대한 상세설명
조금 더 간단한 예제로 고정하기를 이해해 봅시다. 위의 문제의 핵심은 '러스트에서 자기참조 타입의 참조를 어떻게 다루는가'입니다.
지금부터 우리의 예제는 다음과 같이 바뀔 겁니다.
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
}
impl Test {
fn new(txt: &str) -> Self {
Test {
a: String::from(txt),
b: std::ptr::null(),
}
}
fn init(&mut self) {
let self_ref: *const String = &self.a;
self.b = self_ref;
}
fn a(&self) -> &str {
&self.a
}
fn b(&self) -> &String {
assert!(!self.b.is_null(), "Test::b called without Test::init being called first");
unsafe {&*(self.b)}
}
}
Test는 a와 b 필드의 값에 대한 참조를 얻는 메소드를 제공합니다. b는 a에
대한 참조이기 때문에 b에 포인터를 사용합니다. 왜냐하면, 러스트의 빌림규칙에
따라 이 라이프타임을 정의할 수 없기 때문입니다. 이 구조체가 바로 자기-참조
구조체라고 불리는 것입니다.
아래 예제를 실행하면 알 수 있듯이, 어느 데이타도 여기저기 움직이지 않는다면 위 예제는 잘 작동할 겁니다.
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); println!("a: {}, b: {}", test2.a(), test2.b()); } #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), } } // 자기-참조를 실제로 설정할 `init` 메소드 fn init(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe {&*(self.b)} } }
예상한 대로 출력됩니다.
a: test1, b: test1
a: test2, b: test2
그럼 test1과 test2를 스왑하여 데이터를 움직여보고, 무슨 일이 생기는 지 봅시다.
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); std::mem::swap(&mut test1, &mut test2); println!("a: {}, b: {}", test2.a(), test2.b()); } #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), } } fn init(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { unsafe {&*(self.b)} } }
단순하게 생각하면, 아래처럼 두 번 다 test1의 디버그 내용이 출력될 것이라
생각하기 십상입니다:
a: test1, b: test1
a: test1, b: test1
하지만 실제 출력은 다음과 같습니다:
a: test1, b: test1
a: test1, b: test2
스왑 이후에도, test2.b에 대한 포인터는 현재 test1 내부에 있는 옛
위치를 여전히 가리킵니다. 이 구조체는 더 이상 자기-참조적이지
않으며, 다른 객체 안에 있는 필드를 가리키는 포인터를 가지게 됩니다. 즉,
test2의 라이프타임에 매여있는 test2.b의 라이프타임을 더이상 신뢰할 수 없다는
뜻입니다.
만약 아직도 이해가 되지 않는다면, 아래 코드가 확실히 이해시켜 줄 것입니다.
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); std::mem::swap(&mut test1, &mut test2); test1.a = "I've totally changed now!".to_string(); println!("a: {}, b: {}", test2.a(), test2.b()); } #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), } } fn init(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe {&*(self.b)} } }
아래 그림은 이 내용들을 도식화합니다.
Fig 1: 스왑 전 후
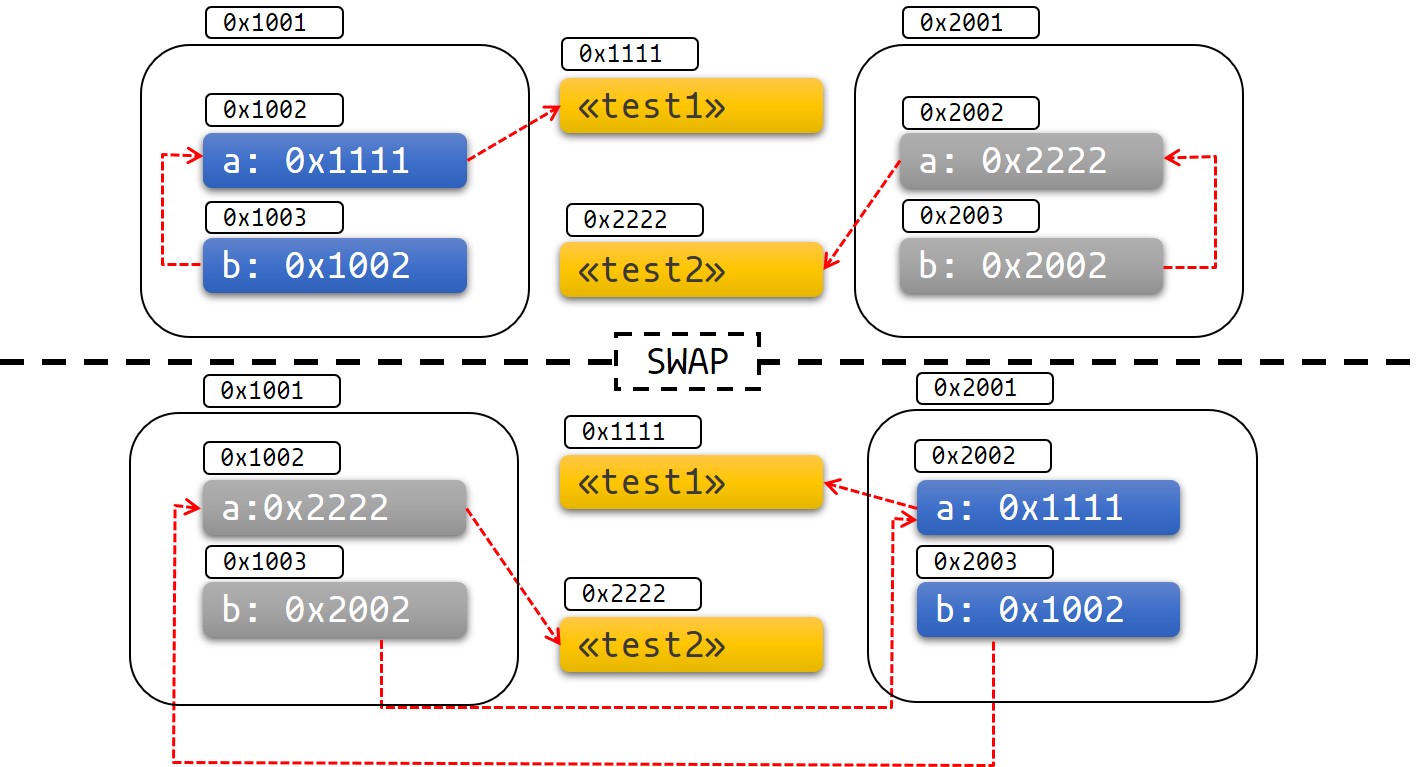
다른 특별한 방법도 있겠지만, 위와 같이 정의되지 않은 동작(UB)과 실패를 그림으로 표현하면 이해하기 쉽습니다.
고정하기 실전문제
고정하기와 Pin 타입으로 어떻게 이 문제를 해결하는지 알아봅시다.
Pin 타입은 포인터 타입들을 랩핑하여, 포인터가 가리키는 Unpin을 구현하지 않은
값들이 이동하지 않음을 보장합니다. 예를 들어, Pin<&mut T>, Pin<&T>,
Pin<Box<T>>는 모두 T: !Unpin이라면 T가 이동하지 않음을 보장합니다.
대부분의 타입들은 이동해도 문제가 없습니다. 이러한 타입들은 Unpin이라는
트레잇을 구현합니다. Unpin 타입을 가리키는 포인터들은 자유롭게 Pin 안에
넣거나 꺼낼 수 있습니다. 예를 들어, u8은 Unpin이기 때문에 Pin<&mut u8>은
그냥 평범한 &mut u8처럼 작동합니다.
하지만, 고정된 다음에는 움직일 수 없는 타입들은 !Unpin이라는 마커를 가지고
있습니다. async/await에 의해 만들어진 future가 그 예시입니다.
스택에 고정하기
다시 예제로 돌아가서, Pin을 이용하면 우리의 문제를 해결할 수 있습니다. 고정된
포인터를 사용하면 우리의 예제가 어떻게 바뀌는지 살펴봅시다.
use std::pin::Pin;
use std::marker::PhantomPinned;
#[derive(Debug)]
struct Test {
a: String,
b: *const String,
_marker: PhantomPinned,
}
impl Test {
fn new(txt: &str) -> Self {
Test {
a: String::from(txt),
b: std::ptr::null(),
_marker: PhantomPinned, // 이렇게 하면 `Test`의 타입을 `!Unpin`으로 만듦
}
}
fn init(self: Pin<&mut Self>) {
let self_ptr: *const String = &self.a;
let this = unsafe { self.get_unchecked_mut() };
this.b = self_ptr;
}
fn a(self: Pin<&Self>) -> &str {
&self.get_ref().a
}
fn b(self: Pin<&Self>) -> &String {
assert!(!self.b.is_null(), "Test::b called without Test::init being called first");
unsafe { &*(self.b) }
}
}
우리의 타입이 !Unpin을 구현한다면 객체를 스택에 고정하는 행위는 항상
unsafe할 것입니다. 여러분이 unsafe 코드를 직접 작성하지 않고 스택에
고정하려면, pin_utils 같은 크레잇을 사용하면 됩니다.
아래처럼, 객체 test1과 test2를 스택에 고정합시다.
pub fn main() { // test1은 초기화되기 전에는 이동해도 안전합니다. let mut test1 = Test::new("test1"); // `test1`이 다시 액세스되는 것을 막기 위해 어떻게 `test1`을 쉐도우하는지 확인해 두세요 let mut test1 = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1.as_mut()); let mut test2 = Test::new("test2"); let mut test2 = unsafe { Pin::new_unchecked(&mut test2) }; Test::init(test2.as_mut()); println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref())); println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref())); } use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), // 우리의 타입을 `!Unpin`으로 만듭니다. _marker: PhantomPinned, } } fn init(self: Pin<&mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
자, 만약 지금 우리가 데이터를 움직이려고 하면, 컴파일 에러가 발생합니다.
pub fn main() { let mut test1 = Test::new("test1"); let mut test1 = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1.as_mut()); let mut test2 = Test::new("test2"); let mut test2 = unsafe { Pin::new_unchecked(&mut test2) }; Test::init(test2.as_mut()); println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref())); std::mem::swap(test1.get_mut(), test2.get_mut()); println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref())); } use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), _marker: PhantomPinned, // 우리의 타입을 `!Unpin`으로 만듭니다. } } fn init(self: Pin<&mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
타입 시스템은 우리가 데이터를 움직이지 못하게 막아줍니다.
스택에 고정하기는
unsafe를 사용하므로 항상 여러분이 보증해야 한다는 점을 명심하세요.'a라이프타임 안에서는&'a mut T가 _가리키는 값_이 고정된지만,'a가 끝난 다음에도&'a mut T가 가리키는 데이터가 안 움직였는지 알 수는 없습니다. 만약&'a mut T가 가리키는 데이터가'a가 끝난 다음에 움직인다면 Pin 규칙을 어기게 될 것입니다.
원 변수를 쉐도우하는 것을 깜빡하기 쉽습니다. 왜냐하면, (Pin 규칙을 어기는) 아래 코드처럼,
Pin을 드랍하고 나서,&'a mut T다음에 데이타를 움직일 가능성이 있기 때문입니다.fn main() { let mut test1 = Test::new("test1"); let mut test1_pin = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1_pin.as_mut()); drop(test1_pin); println!(r#"test1.b points to "test1": {:?}..."#, test1.b); let mut test2 = Test::new("test2"); mem::swap(&mut test1, &mut test2); println!("... and now it points nowhere: {:?}", test1.b); } use std::pin::Pin; use std::marker::PhantomPinned; use std::mem; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), // This makes our type `!Unpin` _marker: PhantomPinned, } } fn init<'a>(self: Pin<&'a mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a<'a>(self: Pin<&'a Self>) -> &'a str { &self.get_ref().a } fn b<'a>(self: Pin<&'a Self>) -> &'a String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
힙 역역에 고정하기
!Unpin타입을 힙에 고정하면 우리 데이타에 안정적인 주소를 부여하게 됩니다.
그래서 우리가 가리키는 데이터는 고정되고 나면 움직일 수 없습니다. 스택에
고정하기와 대조적으로, 데이터가 객체의 수명주기동안 고정됩니다.
use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Pin<Box<Self>> { let t = Test { a: String::from(txt), b: std::ptr::null(), _marker: PhantomPinned, }; let mut boxed = Box::pin(t); let self_ptr: *const String = &boxed.a; unsafe { boxed.as_mut().get_unchecked_mut().b = self_ptr }; boxed } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { unsafe { &*(self.b) } } } pub fn main() { let test1 = Test::new("test1"); let test2 = Test::new("test2"); println!("a: {}, b: {}",test1.as_ref().a(), test1.as_ref().b()); println!("a: {}, b: {}",test2.as_ref().a(), test2.as_ref().b()); }
몇몇 함수들은 future가 Unpin 타입일 것을 요구합니다. Unpin이 아닌 Future나
Stream을 Unpin 타입을 요구하는 함수와 함께 사용하기 위해서는, 먼저
(Pin<Box<T>>을 만든다면) Box::pin이나 (Pin<&mut T>를 만든다면)
pin_utils::pin_mut! 매크로를 사용하여 값을 고정해야 합니다. Pin<Box<Fut>>와
Pin<&mut Fut> 둘 다 future처럼 사용될 수 있으며, 둘 다 Unpin을 구현합니다.
예를 들어:
use pin_utils::pin_mut; // `pin_utils`는 crates.io에 있는 가벼운 crate입니다.
// `Unpin`을 구현하는 `Future`를 취하는 함수
fn execute_unpin_future(x: impl Future<Output = ()> + Unpin) { /* ... */ }
let fut = async { /* ... */ };
execute_unpin_future(fut); // 오류: `fut`은 `Unpin` 트레잇을 구현하지 않음
// Pinning with `Box`:
let fut = async { /* ... */ };
let fut = Box::pin(fut);
execute_unpin_future(fut); // OK
// Pinning with `pin_mut!`:
let fut = async { /* ... */ };
pin_mut!(fut);
execute_unpin_future(fut); // OK
정리
-
T: Unpin(기본값)이라면Pin<'a, T>는&'a mut T와 전적으로 동일합니다. 다르게 표현하자면,Unpin은 "이 타입은 고정되었을지라도 이동되어도 됨"을 의미합니다. 따라서Pin은 해당 타입에 대해 효과가 없습니다. -
T: !Unpin일 때, 고정된 T에 대하여&mut T를 얻으려면 unsafe가 필요합니다. -
대부분의 표준 라이브러리 타입들은
Unpin을 구현합니다. 여러분이 러스트에서 사용할 대부분의 "평범한" 타입들도 마찬가지입니다. async/await에 의해 생성된Future는 이 규칙에 예외입니다. -
nightly에서는 feature flag를 설정하면 어떤 타입에
!Unpin바운드를 추가할 수 있습니다. stable에서는 타입에std::marker::PhantomPinned를 추가하면 됩니다. -
데이타를 스택이나 힙에 고정할 수 있습니다.
-
!Unpin객체를 스택에 고정하려면unsafe가 필요합니다. -
!Unpin객체를 힙에 고정할 때는unsafe가 필요 없습니다.Box::pin을 사용하면 간단하게 할 수 있습니다. -
T: !Unpin인 고정된 데이터에 대해서는, 여러분이 그 데이터의 메모리가 고정된 순간부터 drop이 호출되기 전까지 무효화되거나 용도변경되지 않음(불변성)을 유지할 책임이 있습니다. 이는 고정 규칙에서 중요한 부분입니다.
Stream 트레잇
Stream 트레잇은 Future와 비슷하지만 작업을 끝내기 전 여러 값을 산출할 수
있다는 점에서 다릅니다. Stream은 표준 라이브러리의 Iterator 트레잇과
비슷하다고 보면 됩니다.
trait Stream {
/// 스트림이 양보하는 값의 타입
type Item;
/// 스트림에 있는 다음 아이템을 해결하려 한다.
/// 아직 준비가 안 됐으면 `Poll::Pending`, 준비가 되었으면 `Poll::Ready(Some(x))`
/// , 끝났으면 `Poll::Ready(None)`을 반환한다.
fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>)
-> Poll<Option<Self::Item>>;
}
Stream의 한 가지 예시로 futures 크레이트에 있고 채널 타입에 쓰이는
Receiver가 있습니다. Sender 단에서 값을 보낼 때마다 Some(val)을 내놓고,
Sender가 드랍되고 모든 대기 메시지를 다 받았을 때에는 None을 반환합니다.
async fn send_recv() {
const BUFFER_SIZE: usize = 10;
let (mut tx, mut rx) = mpsc::channel::<i32>(BUFFER_SIZE);
tx.send(1).await.unwrap();
tx.send(2).await.unwrap();
drop(tx);
// `StreamExt::next` 는 `Iterator::next`와 같지만,
// `Future<Output = Option<T>>`을 구현한 타입을 반환한다.
assert_eq!(Some(1), rx.next().await);
assert_eq!(Some(2), rx.next().await);
assert_eq!(None, rx.next().await);
}
반복과 동시성
동기적 Iterator와 같이 Stream에서 값을 반복하고 처리하는 여러 가지 방법이 있습니다.
map, filter, fold와 같은 콤비네이터 방식과 try_map, try_filter, try_fold와
같이 오류가 생기면 바로 종료하는 방식의 메소드가 있습니다.
슬프게도 for 반복문은 Stream과 같이 사용할 수 없지만, 명령형 코드를 위해
while let과 next/try_next 함수를 쓸 수 있습니다.
async fn sum_with_next(mut stream: Pin<&mut dyn Stream<Item = i32>>) -> i32 {
use futures::stream::StreamExt; // `next`를 쓰기 위함
let mut sum = 0;
while let Some(item) = stream.next().await {
sum += item;
}
sum
}
async fn sum_with_try_next(
mut stream: Pin<&mut dyn Stream<Item = Result<i32, io::Error>>>,
) -> Result<i32, io::Error> {
use futures::stream::TryStreamExt; // `try_next`를 쓰기 위함
let mut sum = 0;
while let Some(item) = stream.try_next().await? {
sum += item;
}
Ok(sum)
}
하지만 우리가 단지 한 시점에 요소 한 개만 처리하고 있다면 잠재적으로 동시성의
기회를 내다버린 것과 다를 바 없습니다. 이 점이 바로 처음부터 비동기 코드를 써야 하는
이유입니다. 한 스트림 안에서 여러 아이템을 동시에 다루기 위해
for_each_concurrent와 try_for_each_concurrent 메소드를 사용하시기 바랍니다.
async fn jump_around(
mut stream: Pin<&mut dyn Stream<Item = Result<u8, io::Error>>>,
) -> Result<(), io::Error> {
use futures::stream::TryStreamExt; // `try_for_each_concurrent`를 쓰기 위함
const MAX_CONCURRENT_JUMPERS: usize = 100;
stream.try_for_each_concurrent(MAX_CONCURRENT_JUMPERS, |num| async move {
jump_n_times(num).await?;
report_n_jumps(num).await?;
Ok(())
}).await?;
Ok(())
}
여러개의 future를 동시에 실행하기
지금까지, 대부분의 future를 현재의 태스크를 Future가 완성될 때까지 블록하는
.await로 실행시켰습니다. 그러나, 진짜 비동기 어플리케이션은 종종 몇개의 다른
작업을 동시에 실행할 필요가 있습니다.
이 장에서는 여러개의 비동기 작업들을 동시에 싱행하는 몇가지 방법들을 배울 것입니다.
join!: future들이 모두 완성될 때까지 기다림select!: 여러 future 중에 한개가 완료될 때까지 기다림- 스포닝 : 한 개의 future를 완성될 때까지 주변에서 실행하는 최상위 태스크를 만듦
FuturesUnordered: future들의 그룹. 각각의 하위future의 결과를 산출함
join!
futures::join 매크로는 여러개의 다른 future를 동시에 실행하여 모두 완성될
때까지 기다리게 해줍니다.
join!
여러개의 비동기 작업을 진행할 때, 단순하게 .await를 순차적으로 사용하는 식으로
만들기 쉽습니다.
async fn get_book_and_music() -> (Book, Music) {
let book = get_book().await;
let music = get_music().await;
(book, music)
}
그런데, 이렇게 하면 필요한 만큼 성능을 낼 수 없습니다. 왜냐하면, get_book이
완성될 때까지 get_music을 시작하려 하지 않을 것이기 때문입니다. 몇몇 다른
언어에서는, future가 완성될 때까지 주변적으로(ambiently) 실행되는 방식을
사용하기도 합니다. 이 방식에서는 처음부터 각 async fn을 호출하여 future들을
시작하고, 둘 모두를 기다림으로써, 두 작업이 동시에 실행될 수 있습니다.
// WRONG -- 따라하지 마시오
async fn get_book_and_music() -> (Book, Music) {
let book_future = get_book();
let music_future = get_music();
(book_future.await, music_future.await)
}
하지만, 실제 러스트의 future는 .await될 때까지 아무것도 하지 않습니다. 따라서,
위의 두 코드 스니펫들은 둘 다 book_future와 music_future를 동시가 아닌
순차적으로 실행한다는 의미입니다. 두 future를 진짜 동시에 실행하려면
futures::join!을 사용하세요:
use futures::join;
async fn get_book_and_music() -> (Book, Music) {
let book_fut = get_book();
let music_fut = get_music();
join!(book_fut, music_fut)
}
join!이 반환한 값은 각 Future가 출력한 값으로 구성된 튜플입니다.
try_join!
Result를 반환하는 future들에는 join!말고 try_join!을 사용하는 게 좋습니다.
join!은 모든 하위 future들이 완성되었을 때에만 완성되므로, 하위 future 들 중
하나가 Err을 반환하였더라도 나머지 future들을 계속 처리할 것입니다.
join!과 다르게, try_join!은 하위 future 중 하나가 에러를 반환하면 즉시 완성될 것입니다.
use futures::try_join;
async fn get_book() -> Result<Book, String> { /* ... */ Ok(Book) }
async fn get_music() -> Result<Music, String> { /* ... */ Ok(Music) }
async fn get_book_and_music() -> Result<(Book, Music), String> {
let book_fut = get_book();
let music_fut = get_music();
try_join!(book_fut, music_fut)
}
try_join!에 전달된 future들은 모두 같은 타입의 에러를 반환해야 한다는 점을
명심하세요. 에러 타입을 일치시키기 위해 futures::future::TryFutureExt 모듈의
.map_err(|e| ...)과 .err_into() 함수를 사용해 보세요.
use futures::{
future::TryFutureExt,
try_join,
};
async fn get_book() -> Result<Book, ()> { /* ... */ Ok(Book) }
async fn get_music() -> Result<Music, String> { /* ... */ Ok(Music) }
async fn get_book_and_music() -> Result<(Book, Music), String> {
let book_fut = get_book().map_err(|()| "Unable to get book".to_string());
let music_fut = get_music();
try_join!(book_fut, music_fut)
}
select!
futures::select 매크로를 사용하면 여러 future를 동시에 실행하면서, 어떤
future라도 완성되면 사용자가 바로 반응할 수 있습니다.
#![allow(unused)] fn main() { use futures::{ future::FutureExt, // `.fuse()`에 필요 pin_mut, select, }; async fn task_one() { /* ... */ } async fn task_two() { /* ... */ } async fn race_tasks() { let t1 = task_one().fuse(); let t2 = task_two().fuse(); pin_mut!(t1, t2); select! { () = t1 => println!("task one completed first"), () = t2 => println!("task two completed first"), } } }
위의 함수는 t1과 t2 둘 다 동시에 실행할 것입니다. 둘 중에 하나가 끝나면,
대응하는 핸들러가 println!을 호출하고, 위 함수는 나머지 태스크를 완성하지 않고
바로 종료됩니다.
select의 기본 문법은 <pattern> = <expression> => <code>,이고, select에
넣을 future 개수만큼 반복하면 됩니다.
default => ... 와 complete => ...
또한 select는 default와 complete 분기를 지원합니다.
default 분기는 select에 넣어진 future들 중 아무것도 완성되지 않았으면
실행됩니다. 따라서 default 분기가 있는 select는 항상 즉시 반환합니다. 다른
어떤 future도 준비되지 않았으면 defualt가 실행되기 때문입니다.
complete 분기는 select에 넣어진 모든 future가 모두 완성되어 더 이상 진행할
일이 없는 경우를 다루기 위해 사용됩니다. complete 분기는 select!를 반복문
안에 넣을 때 유용합니다.
#![allow(unused)] fn main() { use futures::{future, select}; async fn count() { let mut a_fut = future::ready(4); let mut b_fut = future::ready(6); let mut total = 0; loop { select! { a = a_fut => total += a, b = b_fut => total += b, complete => break, default => unreachable!(), // 실행되지 않음(future들은 준비되자마자 완성됨) }; } assert_eq!(total, 10); } }
Unpin과 FusedFuture로 상호작용하기
위 첫 번째 예제에서, 여러분은 두 async fn가 반환한 future에 대해 pin_mut으로
고정하고, .fuse()를 호출해야 한다는 점을 인지했을 겁니다. select안에서
사용된 future들은 Unpin, FusedFuture 트레잇 둘 다 구현해야 하기 때문에, 이
호출들이 필요합니다.
select가 사용하는 future는 값으로 전달되지 않고 가변 참조로 전달되기 때문에,
Unpin이 필요합니다. future의 소유권을 취하지 않기 때문에, 미완성된 future는
select를 호출한 다음에도 재사용 할 수 있습니다.
비슷하게, select는 이미 완성된 future를 poll하면 안되기 때문에, FusedFuture
트레잇이 필요합니다. FusedFuture는 future에 의해 구현되며, 자신이 완성되었는지
여부를 추적합니다. FusedFuture는 아직 완성되지 않은 future만 골라서 폴링할 수
있게 해주기 때문에 select를 반복문 안에서 사용할 수 있게 됩니다. 이는 위
예제에서 a_fut이나 b_fut가 반복문 2회차 때에 완성되는 것을 보면 알 수
있습니다. future::ready가 반환한 future가 FusedFuture를 구현하기 때문에,
select가 그 future를 다시 poll하지 못하게 할 수 있습니다.
스트림은 같은 기능을 하는 FusedStream 트레잇을 가지고 있음을 알아두세요.
FusedStream 트레잇을 구현하거나, .fuse()를 사용하여 래핑한 스트림은
.next() / .try_next()을 통해 FusedFuture를 뱉을 것입니다.
#![allow(unused)] fn main() { use futures::{ stream::{Stream, StreamExt, FusedStream}, select, }; async fn add_two_streams( mut s1: impl Stream<Item = u8> + FusedStream + Unpin, mut s2: impl Stream<Item = u8> + FusedStream + Unpin, ) -> u8 { let mut total = 0; loop { let item = select! { x = s1.next() => x, x = s2.next() => x, complete => break, }; if let Some(next_num) = item { total += next_num; } } total } }
Fuse와 FuturesUnordered를 이용한 select 루프 내부에서의 동시적 태스크
Fuse:terminated() 함수는 눈에 잘 띄지는 않지만 유용한 함수입니다. 이 함수는
이미 종료되어 비어있지만, 나중에 필요할 때, 실행할 future를 넣어서 실행할 수 있는
future를 만들어 줍니다.
이 함수는 select 루프가 유효한 동안에 실행될 필요가 있지만 select 루프 자체
안에서 만들어지는 태스크가 있을 경우 유용합니다.
.select_next_some() 함수의 용도에 유의하세요. 이 함수는 스트림이 반환한
Some(_) 값에 대응하는 분기를 실행할 때만 select와 함께 사용될 수 있고.
None은 무시할 겁니다.
#![allow(unused)] fn main() { use futures::{ future::{Fuse, FusedFuture, FutureExt}, stream::{FusedStream, Stream, StreamExt}, pin_mut, select, }; async fn get_new_num() -> u8 { /* ... */ 5 } async fn run_on_new_num(_: u8) { /* ... */ } async fn run_loop( mut interval_timer: impl Stream<Item = ()> + FusedStream + Unpin, starting_num: u8, ) { let run_on_new_num_fut = run_on_new_num(starting_num).fuse(); let get_new_num_fut = Fuse::terminated(); pin_mut!(run_on_new_num_fut, get_new_num_fut); loop { select! { () = interval_timer.select_next_some() => { // 타이머가 경과되었음. 아직 실행되지 않고 있는 future가 있다면, // 새 `get_new_num_fut`를 시작 if get_new_num_fut.is_terminated() { get_new_num_fut.set(get_new_num().fuse()); } }, new_num = get_new_num_fut => { // 새 숫자가 도착함 -- 새 `run_on_new_num_fut`를 시작하고 예전 // 것을 드랍함. run_on_new_num_fut.set(run_on_new_num(new_num).fuse()); }, // `run_on_new_num_fut`를 실행 () = run_on_new_num_fut => {}, // 모든 future가 완성되었다면 패닉. 왜냐하면 `indefinitely`는 값들을 // 무기한으로 내야(yield) 함 complete => panic!("`interval_timer` completed unexpectedly"), } } } }
같은 future의 여러 복사본을 동시에 실행할 필요가 있을 때에는 FuturesUnordered
타입을 사용하세요. 아래 예제는 위 예제랑 비슷하지만, run_on_new_num_fut의
복사본이 생겨도 중단하지 않고 각 복사본을 완성될때까지 실행한다는 점이 다릅니다.
또한, 아래 예제는 run_on_new_num_fut가 반환한 값을 출력할 것입니다.
#![allow(unused)] fn main() { use futures::{ future::{Fuse, FusedFuture, FutureExt}, stream::{FusedStream, FuturesUnordered, Stream, StreamExt}, pin_mut, select, }; async fn get_new_num() -> u8 { /* ... */ 5 } async fn run_on_new_num(_: u8) -> u8 { /* ... */ 5 } // `get_new_num`로부터 나온 마지막 숫자를 가지고 `run_on_new_num`를 실행 // // `get_new_num`은 타이머가 경과될 때마다 즉시 현재 실행중인 `run_on_new_num`을 // 취소하고 새 반환값으로 대체하면서 재시작됨. async fn run_loop( mut interval_timer: impl Stream<Item = ()> + FusedStream + Unpin, starting_num: u8, ) { let mut run_on_new_num_futs = FuturesUnordered::new(); run_on_new_num_futs.push(run_on_new_num(starting_num)); let get_new_num_fut = Fuse::terminated(); pin_mut!(get_new_num_fut); loop { select! { () = interval_timer.select_next_some() => { // 타이머 경과됨. 실행중인 `get_new_num_fut`이 없다면 새로 // 시작함. if get_new_num_fut.is_terminated() { get_new_num_fut.set(get_new_num().fuse()); } }, new_num = get_new_num_fut => { // 새 숫자가 도착함 -- 새 `run_on_new_num_fut`를 시작함. run_on_new_num_futs.push(run_on_new_num(new_num)); }, // `run_on_new_num_futs`를 실행하고 완성된 `run_on_new_num_futs`가 // 있는 지 확인함 res = run_on_new_num_futs.select_next_some() => { println!("run_on_new_num_fut returned {:?}", res); }, // 모든 것이 완성되었다면 패닉. 왜냐하면 `interval_timer`는 값을 무기한으로 내야 함 complete => panic!("`interval_timer` completed unexpectedly"), } } } }
알아두면 좋을 요령들
러스트의 async 지원은 아직 많이 새롭습니다. 그리고 매우 필요한 몇몇 기능들은
아직 개발중에 있습니다. 진단루틴도 약간 수준이하입니다. 이 장에서는 자주 나오는
불편한 부분들에 대해 논의하고, 이를 회피하는 요령에 대해 설명합니다.
async 블록 안에서의 ?
async fn 안에서와 마찬가지로, async 블록들 안에서 ?의 사용도 보편적입니다.
하지만, async 블록의 반환 타입은 명시적으로 규정되지 않았기 때문에, 컴파일러가
async블록의 에러 타입을 추론하는 데 실패할 것입니다.
예를 들어, 아래 코드는
#![allow(unused)] fn main() { struct MyError; async fn foo() -> Result<(), MyError> { Ok(()) } async fn bar() -> Result<(), MyError> { Ok(()) } let fut = async { foo().await?; bar().await?; Ok(()) }; }
아래 에러를 발생시킬 것입니다.
error[E0282]: type annotations needed
--> src/main.rs:5:9
|
4 | let fut = async {
| --- consider giving `fut` a type
5 | foo().await?;
| ^^^^^^^^^^^^ cannot infer type
불행하게도, "fut에 타입을 부여하는" 방법이나, 명시적으로 async블록의 반환
타입을 지정하는 방법은 현재 존재하지 않습니다. 이 문제를 해결하기 위해서,
async블록에 성공과 에러의 타입을 제공하기 위해 아래와 같이 "turbofish"
연산자를 사용하세요.
#![allow(unused)] fn main() { struct MyError; async fn foo() -> Result<(), MyError> { Ok(()) } async fn bar() -> Result<(), MyError> { Ok(()) } let fut = async { foo().await?; bar().await?; Ok::<(), MyError>(()) // <- 이 곳의 명시적 타입 주해에 유의할 것. }; }
Send 추정
몇몇 async fn 상태기계는 스레드 간 이동에 안전하지만 나머지는 그렇지 않습니다.
async fn Future가 Send인지 여부는 Send가 아닌 타입이 .await의 위치
앞뒤로 걸쳐서 유지되는지 여부에 달려 있습니다. 값들이 .await의 위치 앞뒤로
걸쳐서 유지될 가능성이 있을 때, 컴파일러는 async fn Future가 Send인지
여부를 추정하려고 최선을 다합니다. 하지만, 이런 분석은 오늘날 많은 경우에 너무
보수적입니다.
예를 들어, 간단한 비(非) Send 타입이 Rc를 가지고 있을지도 모른다고
가정해봅시다.
#![allow(unused)] fn main() { use std::rc::Rc; #[derive(Default)] struct NotSend(Rc<()>); }
async fn이 최종적으로 반환한 Future 타입(역주: 아래 예제에서 foo()가 반환한
future)이 Send이어야만 하는 경우에도, NotSend 타입의 변수들이 임시값이라면
async fn 안에서도 간편하게 사용할 수 있습니다.
use std::rc::Rc; #[derive(Default)] struct NotSend(Rc<()>); async fn bar() {} async fn foo() { NotSend::default(); bar().await; } fn require_send(_: impl Send) {} fn main() { require_send(foo()); }
하지만, foo를 수정하여 한 변수 안에 NotSend를 저장하는 코드를 추가한다면, 이
예제는 컴파일되지 않습니다.
use std::rc::Rc; #[derive(Default)] struct NotSend(Rc<()>); async fn bar() {} async fn foo() { let x = NotSend::default(); bar().await; } fn require_send(_: impl Send) {} fn main() { require_send(foo()); }
error[E0277]: `std::rc::Rc<()>` cannot be sent between threads safely
--> src/main.rs:15:5
|
15 | require_send(foo());
| ^^^^^^^^^^^^ `std::rc::Rc<()>` cannot be sent between threads safely
|
= help: within `impl std::future::Future`, the trait `std::marker::Send` is not implemented for `std::rc::Rc<()>`
= note: required because it appears within the type `NotSend`
= note: required because it appears within the type `{NotSend, impl std::future::Future, ()}`
= note: required because it appears within the type `[static generator@src/main.rs:7:16: 10:2 {NotSend, impl std::future::Future, ()}]`
= note: required because it appears within the type `std::future::GenFuture<[static generator@src/main.rs:7:16: 10:2 {NotSend, impl std::future::Future, ()}]>`
= note: required because it appears within the type `impl std::future::Future`
= note: required because it appears within the type `impl std::future::Future`
note: required by `require_send`
--> src/main.rs:12:1
|
12 | fn require_send(_: impl Send) {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
For more information about this error, try `rustc --explain E0277`.
이 에러는 문제를 정확히 나타내 줍니다. x를 변수에 저장한다면, x는 async fn이 다른 스레드에서 동작하고 있을 시점인 .await를 지난 다음에야 드랍될
것입니다. Rc는 Send가 아니기 때문에, Rc가 스레드 사이를 이동하게 만드는
것은 위험합니다. 이에 대한 간단한 해법은 .await이전에 Rc를 drop하는
것입니다만, 불행하게도 지금은 해당되지 않습니다.
이 이슈를 해결하기 위해서는, 모든 비 Send 변수를 캡슐화하는 블록 범위를
도입해야 할 것입니다. 이렇게 하면, 이 변수들이 .await 포인트에 걸쳐 존재하지
않는다는 사실을 컴파일러가 알게 하기 쉽습니다.
use std::rc::Rc; #[derive(Default)] struct NotSend(Rc<()>); async fn bar() {} async fn foo() { { let x = NotSend::default(); } bar().await; } fn require_send(_: impl Send) {} fn main() { require_send(foo()); }
재귀
내부적으로, async fn은 .await하는 하위 Future를 갖는 상태기계 타입을
만듭니다. 때문에, async fn을 재귀적으로 사용하기 살짝 까다롭습니다. 왜냐하면,
결과를 도출할 상태기계 타입이 그 자신을 포함해야 하기 때문입니다.
#![allow(unused)] fn main() { async fn step_one() { /* ... */ } async fn step_two() { /* ... */ } struct StepOne; struct StepTwo; // This function: async fn foo() { step_one().await; step_two().await; } // generates a type like this: enum Foo { First(StepOne), Second(StepTwo), } // So this function: async fn recursive() { recursive().await; recursive().await; } // generates a type like this: enum Recursive { First(Recursive), Second(Recursive), } }
위 예제는 무한한 크기의 타입을 만들기 때문에 작동하지 않습니다. 컴파일러 오류는 다음과 같습니다.
error[E0733]: recursion in an `async fn` requires boxing
--> src/lib.rs:1:22
|
1 | async fn recursive() {
| ^ an `async fn` cannot invoke itself directly
|
= note: a recursive `async fn` must be rewritten to return a boxed future.
제대로 작동하게 하기 위해서는, Box를 이용해 우회접근해야 합니다. 불행하게도,
컴파일러의 제한에 따라 Box::pin으로 recursive() 호출을 감싸는 것만으로는
충분하지 않습니다. 제대로 하려면은, 아래 예제처럼 recursive를 .boxed()된 비
async 블록 안에 넣어야 합니다.
#![allow(unused)] fn main() { use futures::future::{BoxFuture, FutureExt}; fn recursive() -> BoxFuture<'static, ()> { async move { recursive().await; recursive().await; }.boxed() } }
트레잇 내부의 async
현재로서는, 트레잇 안에서 async fn를 사용할 수 없습니다. 이유가 좀 복잡한데,
향후 이 제약을 해소하기 위한 계획이 있긴 합니다.
Rust가 언어 차원에서 공식지원하기 전 까지는, crates.io에 있는 async-trait 크레잇으로 트레잇 안에서 async fn을 사용하면 됩니다.
crates.io에 있는 async-trait 크레잇 메소드는 매 함수호출마다 힙영역에 할당할 것입니다. 이 때 발생하는 성능저하가 전체 어플리케이션에 비하면 별로 대단한 것은 아니지만, 초당 수백만 회의 호출이 예상되는 저수준 공용 API에 사용할 때에는 염두에 두어야 합니다.
비동기 생태계
러스트는 현재 비동기 코드를 작성하는 데 극히 필수적인 기능만 제공하고 있습니다. 중요한 것은, 실행자, 태스크, 반응자, 조합자, 그리고 저수준 입출력 future와 트레잇은 아직 표준 라이브러리에서 제공되지 않고 있습니다. 하지만, 커뮤니티에서 제공하는 비동기 생태계가 이러한 갭을 메꾸고 있습니다.
러스트 비동기 협회 팀은 앞으로 이 비동기 책의 예제들을 다양한 런타임을 이용하여 표현하려고 합니다. 이 프로젝트에 관심이 있다면 아래로 연락주세요. Zulip.
비동기 런타임
비동기 런타임은 비동기 어플리케이션을 실행하는 데 사용되는 라이브러리들입니다. 런타임들은 보통 한 개의 반응자와 한 개 이상의 실행자를 포함합니다. 반응자는 비동기 입출력, 프로세스 간 통신 그리고 타이머 같은 외부 이벤트에 대한 구독 메카니즘을 제공합니다. 통상적으로 비동기 런타임에서 구독자는 저수준 입출력 연산을 나타내는 future를 말합니다. 실행자는 태스크들의 스케쥴링과 실행을 처리합니다. 실행자는 태스크의 실행과 일시정지를 계속 추적하고, future를 완성될때까지 poll하고, 또, task가 진행할 수 있을 때 깨우는 역할을 합니다. "실행자(excutor)"라는 용어는 "runtime"과 자주 혼용됩니다. 여기서는 호환되는 트레잇과 기능들이 묶음포장된 런타임을 가리키는 용어로 "생태계(ecosystem)"를 사용할 것입니다.
커뮤니티에서 제공하는 비동기 크레잇들
future 크레잇
futures crate 은 비동기 코드를 작성하는 데 유용한
트레잇과 함수를 포함하고 있습니다. future 크레잇은 Stream, Sing,
AsyncRead, AsyncWrite 트레잇 및 조합자 같은 유틸리티들을 포함합니다. 이
유틸리티들과 트레잇들은 아마 결국에는 표준 라이브러리에 포함될 것입니다.
futures 크레잇은 고유의 실행자를 가지고 있지만, 고유의 반응자는 없습니다.
그래서 futures 크레잇은 비동기 입출력이나 타이머 future의 실행은 지원하지
않습니다.
이 같은 이유로, futures 크레잇은 온전한 런타임으로 여겨지지 않습니다.
futures 크레잇의 유틸리티를 다른 크레잇의 실행자와 함께 사용하는 것이 일반적인
선택지입니다.
인기있는 비동기 런타임
표준 라이브러리에는 비동기 런타임이 전혀 없고, 어느것도 공식적으로 추천되지 않습니다. 다음 크레잇들은 인기있는 런타임들을 제공합니다.
- Tokio: HTTP, gRPC, 추적 프레임웍을 제공하는 인기있는 비동기 생태계
- async-std: 표준 라이브러리 비동기 컴포넌트에 대응하는 크레잇
- smol: 작고 간단한 비동기 런타임으로,
UnixStream이나TcpListener같은 구조체를 래핑하는 데 사용되는Async트레잇을 제공함 - fuchsia-async: Fuchsia 운영체제에서 사용되는 실행자
생태계 호환성 결정하기
모든 비동기 어플리케이션, 프레임웍, 라이브러리들이 서로 호환되는 것은 아니며, 어떤 운영체제나 플랫폼에도 호환되지 않을 수도 있습니다. 대부분의 비동기 코드는 어떤 생태계와도 호환되지만, 몇몇 프레임웍과 라이브러리는 특정 생태계를 요구하기도 합니다. 생태계 요구조건이 항상 문서화되는 것은 아니지만, 라이브러리, 트레잇, 함수가 어떤 생태계에 의존하는지 판단할 수 있는 몇가지 경험칙들이 있습니다.
비동기 입출력, 타이머, 프로세스 또는 태스크 간 통신과 상호작용하는 모든 비동기 코드는 보통 특정 비동기 실행자 또는 반응자에 의존합니다. 그 외 모든 코드, 즉 비동기 표현식, 조합자, 동기화 타입, 스트림 등은 보통 생태계로부터 독립적이고, 중첩된 futures들도 역시 생태계 독립적입니다. 프로젝트를 시작하기 전에, 연관된 비동기 프레임웍과 라이브러리가 서로 호환되는 지, 여러분이 선택한 런타임과는 호환되는 지를 확실히 확인하기를 추천합니다.
특히, Tokio는 mio 반응자를 사용하고, AsyncRead, AsyncWrite을 포함한
비동기 입출력 트레잇의 고유 버전을 정의합니다. Tokio 고유의 구현 때문에,
async-executor crate에 의존하는
async-std와 smol과 호환되지 않고, futures에 정의된 AsyncRead와
AsyncWrite 트레잇과도 호환되지 않습니다.
런타임 요구사항 충돌 문제는 때때로 런타임 안에서 다른 런타임을 호출할 수 있게
해주는 호환성 레이어를 통해 해결될 수 있습니다. 예를 들어, async_compat
crate은 Tokio와 다른 런타임 사이에서 호환성
레이어를 제공합니다.
비동기 API들을 노출하는 라이브러리는 태스크를 생성하거나 라이브러리 고유의 비동기 입출력이나 타이머 future를 정의하지 않는 한, 특정한 실행자나 반응자에 의존해서는 안됩니다. 이상적으로는, 오직 바이너리들만 태스크의 스케줄링과 실행을 책임져야 합니다.
싱글 스레딩 vs 멀티 스레딩 실행자
비동기 실행자는 싱글 또는 멀티 스레딩이 될 수 있습니다. 예를 들어,
async-executor 크레잇은 싱글 스레딩 LocalExecutor와 멀티 스레딩 Executor를
모두 제공합니다.
멀티 스레딩 실행자는 여러 태스크들을 동시에 진행시킵니다. 멀티 스레딩 실행자는 많은 태스크가 존재하는 워크로드에서 실행속도를 크게 높일 수 있습니다만, 보통 태스크 간 데이터 동기화의 오버헤드가 큰 편입니다. 싱글스레드와 멀티스레드 런타임 중 하나를 선택할 때, 성능을 측정해 비교해 볼 것을 권합니다.
태스크는 태스크가 만들어진 스레드와 별도의 스레드 모두에서 실행될 수 있습니다.
비동기 런타임은 보통 별도의 스레드에 태스크를 생성하는 기능을 제공합니다. 만약
태스크가 별도의 스레드에서 실행된다면, 그 태스크들도 여전히 논블로킹이어야
합니다. 태스크들을 멀티 스레딩 실행자에서 스케줄링하기 위해, 그 태스크들은 역시
Send이어야 합니다. 몇몇 런타임들은 생성된 스레드 안에서 실행됨이 보장되는 비
Send 태스크들을 생성하는 기능을 제공합니다. 그런 런타임들은 또한 전용
스레드에서 실행되는 블로킹 태스크들을 생성하는 기능을 제공할 것입니다. 전용
스레드에서 실행되는 블로킹 태스크는 다른 라이브러리의 블로킹 동기적 코드를
실행하는 데 유용하게 사용될 수 있습니다.
마지막 프로젝트: 비동기 러스트로 동시성 웹 서버 만들기
이 장에선, 비동기 러스트로 러스트북의 싱글스레드 기반 웹 서버 만들기 를 수정하여 여러개의 요청을 동시에 수행할 수 있게 할 것입니다.
개요
이 강좌가 끝나면 아래 코드가 만들어 질 것입니다.
src/main.rs:
use std::fs; use std::io::prelude::*; use std::net::TcpListener; use std::net::TcpStream; fn main() { // localhost 7878 포트에서 수신되는 TCP 연결을 listen하기 let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); // 영원히 블록하면서, 이 IP 주소로 들어오는 요청을 처리 for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { // 처음 1024 바이트의 데이터를 스트림으로부터 읽어들임 let mut buffer = [0; 1024]; stream.read(&mut buffer).unwrap(); let get = b"GET / HTTP/1.1\r\n"; // 요청 안의 데이터에 따라 환영인사로 응답하거나 404 에러 let (status_line, filename) = if buffer.starts_with(get) { ("HTTP/1.1 200 OK\r\n\r\n", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND\r\n\r\n", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); // 다시 스트림에 응답을 씀 // 클라이언트에게 응답이 전송될 수 있게 스트림을 플러시함 let response = format!("{status_line}{contents}"); stream.write_all(response.as_bytes()).unwrap(); stream.flush().unwrap(); }
hello.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
404.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
cargo run으로 서버를 실행시켜서 브라우저에서 127.0.0.1:7878에 접속했다면,
페리스의 친근한 인사말을 볼 수 있을 겁니다!
비동기 코드 실행하기
HTTP 서버는 동시에 여러 클라이언트에 동시에 서비스할 수 있어야 합니다. 즉, HTTP 서버는 현재의 요청을 처리하기 전에 기존의 요청이 끝나길 기다려서는 안된다는 말입니다. 러스트북의 예제에서는 모든 연결에 스레드를 하나씩 할당하는 스레드 풀을 만들어서 이 문제를 해결합니다.
여기서는, 스레드를 추가하여 처리성능을 향상시키기 보다, 비동기 코드를 사용하여 같은 효과를 내 봅시다.
handle_connection의 선언을 async fn으로 수정하여 future를 반환하게 합시다.
async fn handle_connection(mut stream: TcpStream) {
//<-- snip -->
}
async를 handle_connection 선언에 추가하면 반환값이 유닛 타입 ()에서
Future<Output=()>을 구현하는 타입으로 변경됩니다.
이 코드를 컴파일하면 작동되지 않을 것이라는 컴파일러 에러가 발생합니다.
$ cargo check
Checking async-rust v0.1.0 (file:///projects/async-rust)
warning: unused implementer of `std::future::Future` that must be used
--> src/main.rs:12:9
|
12 | handle_connection(stream);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_must_use)]` on by default
= note: futures do nothing unless you `.await` or poll them
handle_connection은 그 반환값을 await하거나 poll하지 않았기 때문에, 전혀
실행되지 않을 것입니다. 서버를 실행하고 브라우저에서 127.0.0.1:7878 열면
연결이 거부됨을 알 수 있습니다. 서버가 요청을 처리하지 않는 것입니다.
비동기 코드 안에서 future 그 자제 만으로는 await하거나 poll할 수 없습니다.
즉 future가 완성될 때까지 스케쥴링하고 실행할 비동기 런타임이 필요합니다. 비동기
런타임, executor 그리고 reactor에 대한 자세한 정보를 원한다면 런타임
선택하기 장을 살펴보세요. 런타임
선택하기 장에 나온 모든 런타임은 이 프로젝트에서
동작할 것이지만, 이 예제들에선 aysnc-std 크레잇을 사용하기로 합니다.
Async 런타임 추가
아래 예제는 비동기 런타임(여기서는 async-std)을 사용하도록 리팩토링한 코드를 보여줄 것입니다.
async-std의 #[async_std::main] 속성을 붙이면 비동기 main 함수를 작성할 수 있습니다.
#[async_std::main]을 사용하기 위해서 async-std의 attributes 기능을 Cargo.toml에서
활성화 하세요.
[dependencies.async-std]
version = "1.6"
features = ["attributes"]
첫 번째 단계로, main 함수를 비동기로 전환하고, 비동기 handle_connection이
반환한 future를 await할 것입니다. 그리고 나서, 서버가 어떻게 작동하는 지
테스트할 것입니다. 이렇게 작성한 코드는 아래와 같습니다.
async fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); // 경고: 동시성이 없습니다. handle_connection(stream).await; } }``` 이제 서버가 연결을 동시에 처리할 수 있는 지 테스트해 봅시다. 단순히 `handle_connection`을 비동기로 만들었다고 해서 바로 서버가 여러개의 연결을 동시에 처리할 수 있게 되지는 않습니다. 곧 그 이유를 곧 알게 될 것입니다. 이를 설명하기 위해, 느린 요청 하나로 모의실험해 봅시다. 클라이언트가 `127.0.0.1:7878/sleep`으로 요청을 보냈을 때, 우리 서버는 5초간 잠들 것입니다. ```rust,ignore use async_std::task; async fn handle_connection(mut stream: TcpStream) { let mut buffer = [0; 1024]; stream.read(&mut buffer).unwrap(); let get = b"GET / HTTP/1.1\r\n"; let sleep = b"GET /sleep HTTP/1.1\r\n"; let (status_line, filename) = if buffer.starts_with(get) { ("HTTP/1.1 200 OK\r\n\r\n", "hello.html") } else if buffer.starts_with(sleep) { task::sleep(Duration::from_secs(5)).await; ("HTTP/1.1 200 OK\r\n\r\n", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND\r\n\r\n", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); let response = format!("{status_line}{contents}"); stream.write(response.as_bytes()).unwrap(); stream.flush().unwrap(); }
이는 러스트북의 현재 서버에서 느린 요청을 시뮬레이팅하기와 매우 유사합니다.
우리는 블로킹 함수인 std::thread::sleep대신에 논블로킹 함수인
async_std::task::sleep를 사용하고 있습니다. 코드 한 줄이라도 async fn 안에서
실행되고, await된다면 그 코드는 여전히 스레드를 블록할 수도 있음을 명심하세요.
우리 서버가 연결을 동시에 처리할 수 있는 지 테스트하려면, handle_connection이
논블로킹임을 확인해야 합니다.
서버를 실행하면, 127.0.0.1:7878/sleep에 대한 한 개의 요청이 수신되는 다른
요청들을 5초간 블록하는 것을 확인할 수 있습니다! 그 이유는 우리가
handle_connection을 await하는 동안에 진행될만한 다른 동시성 태스크가 없기
때문입니다. 다음 장에서는 연결을 동시에 처리할 수 있는 비동기 코드를 작성하는
방법에 대해 알아 봅시다.
연결을 동시에 처리하기
지금까지 우리 코드의 문제는 listener.incoming()이 블록하는 반복자라는 점입니다.
executor는 listener가 수신 연결을 기다리는 동안 다른 future를 실행할 수 없고,
우리는 이전 연결을 다 처리할 때까지 새로운 연결을 처리할 수 없습니다.
이를 고치기 위해서 블록하는 반복자인 listener.incoming()을 블록하지 않는 Stream으로
전환시킬 것입니다. Stream은 반복자와 비슷하지만, 비동기적으로 소비될 수
있습니다. 더 많은 정보를 원하시면, Stream 관련
장을 보세요.
블록하는 std::net:TcpListener를 블록하지 않는 async_std::net::TcpListener로
바꿔봅시다. 그리고 async_std::net::TcpStream을 받을 수 있게
handle_connection을 수정합시다.
use async_std::prelude::*;
async fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).await.unwrap();
//<-- snip -->
stream.write(response.as_bytes()).await.unwrap();
stream.flush().await.unwrap();
}
TcpListener의 비동기 버전은 listener.incoming()에 대한 Stream을
구현합니다. 이는 두 가지 이득을 가져다 주는데요, 첫 째는 listener.incoming()이
더 이상 executr를 블록하지 않는다는 점입니다. 이렇게 되면 이제 executor는
처리해야할 수신된 TCP 연결이 없으면 계류중인 future에게 스레드를 양보할 수
있습니다.
두번 째 이득은 Stream에서 가져온 요소들을 Stream의 for_each_concurrent 메소드를
사용하여 선택적으로 동시에 처리할 수 있다는 점입니다.
아래에서는 각 수신된 요구를 동시에 처리하기 위해 이 메소드를 활용할 것입니다.
futures 크레잇의 Stream 트레잇을 import할 필요가 있습니다. 그러면
Cargo.toml은 이제 아래와 같이 될 것입니다.
+[dependencies]
+futures = "0.3"
[dependencies.async-std]
version = "1.6"
features = ["attributes"]
이제 handle_connection을 클로저 함수 안으로 넣어서 각 연결을 동시에 처리할 수
있습니다. 클로저 함수는 각 TcpStream의 소유권을 획득하고, 새 TcpStream이
준비되자마자 실행됩니다.
handle_connection이 블록하지 않는 한, 더 이상 느린 요청은 다른 요청이 완성되지 못하게
방해하지 않을 것입니다.
use async_std::net::TcpListener;
use async_std::net::TcpStream;
use futures::stream::StreamExt;
#[async_std::main]
async fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").await.unwrap();
listener
.incoming()
.for_each_concurrent(/* limit */ None, |tcpstream| async move {
let tcpstream = tcpstream.unwrap();
handle_connection(tcpstream).await;
})
.await;
}
리퀘스트를 병렬적으로 대응하기
우리의 예제는 지금까지 (스레드를 사용하는) 병렬성에 대한 대안으로서 (비동기
코드를 사용하여) 광범위하게 동시성을 구현하였습니다. 하지만, 비동기 코드와
스레드는 상호배제적이지 않습니다. 우리의 예제에서, for_each_concurrent는 한
개의 스레드에서 각 연결을 동시적으로 처리합니다. 하지만 async-std 크레잇은
별도의 스레드에서 태스크를 생성하는 기능을 제공합니다. handle_connection은
Send이면서 논블로킹이기 때문에, async_std::task::spawn과 함께 사용하여도
안전합니다. 아래는 이 예제입니다.
use async_std::task::spawn; #[async_std::main] async fn main() { let listener = TcpListener::bind("127.0.0.1:7878").await.unwrap(); listener .incoming() .for_each_concurrent(/* limit */ None, |stream| async move { let stream = stream.unwrap(); spawn(handle_connection(stream)); }) .await; }
이제 우리는 여러 리퀘스트를 동시에 다루기 위해 동시성과 병행성을 모두 사용하고 있습니다! 더 자세한 내용은 멀티스레딩 실행자 장를 참조하세요.
TCP 서버 테스트하기
handle_connection 함수를 테스트해 봅시다.
먼저, 테스트에 사용될 TcpStream이 필요합니다. 단대단이나 통합 테스트에서는
코드 테스트를 위해 실제 TCP 연결이 필요할 수도 있습니다. 실제 TCP 연결을
사용하여 테스트하는 방법 중 하나는 localhost의 0번 포트에서 리스닝하는
것입니다. 0번 포트는 유효한 유닉스 포트가 아니지만 테스트 목적으로는 작동합니다.
운영체제가 열린 TCP 포트를 하나 골라 줄 것입니다.
하지만, 아래 예제에서는 연결 핸들러에 대한 유닛 테스트를 작성하여, 각각의 입력에
맞는 올바른 응답이 반환되었는지 확인할 것입니다. 유닛 테스트를 격리되고
결정론적이게 만들기 위해, TcpStream을 모조품으로 대체할 것입니다.
먼저, 테스트하기 쉽게 handle_connection의 시그니처를 바꿀
것입니다. 사실 handle_connection는 async_std::net::TcpStream이 꼭 필요한
것은 아닙니다. async_std::io::Read, async_std::io::Write, 그리고 marker::Unpin을 구현하는
어떤 구조체도 가능합니다. 이 내용을 반영하여 타입 시그니처를 바꾸면 모조품을
테스트 용으로 넘겨 줄 수 있게 됩니다.
use std::marker::Unpin;
use async_std::io::{Read, Write};
async fn handle_connection(mut stream: impl Read + Write + Unpin) {
이 트레잇 세 개를 구현하는 TcpStream 모조품을 만들어 봅시다.
먼저, poll_read 메소드 한 개만 있는 Read 트레잇을 구현합시다.
TcpStream 모조품은 읽기 버퍼로 복사되는 어떤 데이터를 가지고 있을 것이고,
복사가 끝나면 poll_read는 읽기가 끝났음을 알리는 Poll::Ready를 반환할 것입니다.
use super::*;
use futures::io::Error;
use futures::task::{Context, Poll};
use std::cmp::min;
use std::pin::Pin;
struct MockTcpStream {
read_data: Vec<u8>,
write_data: Vec<u8>,
}
impl Read for MockTcpStream {
fn poll_read(
self: Pin<&mut Self>,
_: &mut Context,
buf: &mut [u8],
) -> Poll<Result<usize, Error>> {
let size: usize = min(self.read_data.len(), buf.len());
buf[..size].copy_from_slice(&self.read_data[..size]);
Poll::Ready(Ok(size))
}
}
poll_write, poll_flush, 그리고 poll_close라는 세 개의 메소드를 작성해야
할지라도 Write 구현은 매우 간단합니다.
poll_write는 모든 입력 데이터를 TcpStream 모조품으로 복사하고, 완성되면
Poll::Ready를 반환할 것입니다. TcpStream 모조품을 플러싱하거나 닫기 위한
별도 작업이 필요 없기 때문에 poll_flush와 poll_close는 그냥 Poll::Ready를
반환하면 됩니다.
impl Write for MockTcpStream {
fn poll_write(
mut self: Pin<&mut Self>,
_: &mut Context,
buf: &[u8],
) -> Poll<Result<usize, Error>> {
self.write_data = Vec::from(buf);
Poll::Ready(Ok(buf.len()))
}
fn poll_flush(self: Pin<&mut Self>, _: &mut Context) -> Poll<Result<(), Error>> {
Poll::Ready(Ok(()))
}
fn poll_close(self: Pin<&mut Self>, _: &mut Context) -> Poll<Result<(), Error>> {
Poll::Ready(Ok(()))
}
}
마지막으로, TcpStream 모조품은 메모리 상 위치가 안전하게 움직일 수 있다고
알리는 Unpin을 구현해야 합니다.
Unpin에 대한 자세한 정보는 고정하기를 참고하세요.
use std::marker::Unpin;
impl Unpin for MockTcpStream {}
이제 handle_connection 함수를 테스트할 준비가 되었습니다.
MockTcpStream이 임의의 초기 데이터를 가지도록 설정한 다음,
#[async_std::main]의 사용과 유사하게 #[async_std::test] 속성을 이용하여
handle_connection을 실행할 수 있습니다.
handle_connection이 잘 작동함을 확인하기 위해 데이터의 처음 부분을 비교하여 데이터가
MockTcpStream에 제대로 쓰여졌는 지 확인할 것입니다.
use std::fs;
#[async_std::test]
async fn test_handle_connection() {
let input_bytes = b"GET / HTTP/1.1\r\n";
let mut contents = vec![0u8; 1024];
contents[..input_bytes.len()].clone_from_slice(input_bytes);
let mut stream = MockTcpStream {
read_data: contents,
write_data: Vec::new(),
};
handle_connection(&mut stream).await;
let mut buf = [0u8; 1024];
stream.read(&mut buf).await.unwrap();
let expected_contents = fs::read_to_string("hello.html").unwrap();
let expected_response = format!("HTTP/1.1 200 OK\r\n\r\n{}", expected_contents);
assert!(stream.write_data.starts_with(expected_response.as_bytes()));
}
부록 : 이 책의 번역본
영어 외의 언어로 된 번역본